Automatic recovery of the failed postgresql master node is not working with pgpool II
2
votes
1
answer
3540
views
I am new to Postgresql and Pgpool II setup. I have configured the Postgresql HA/Load balancing using Pgpool II and Repmgr.
I have followed the link to do the setup.
The setup consist of 3 nodes and verison of Application and OS is as mentioned below:
**OS version** => CentOS 6.8 (On all the 3 nodes)
**Pgpool node** => 192.168.0.4
**Postgresql Nodes**:
**node1** (Master in read-write mode) => 192.168.0.6
**node2** (Standby node in read only mode) => 192.168.0.7
**Pgpool II version** => pgpool-II version 3.5.0 (ekieboshi).
**Postgresql Version** => PostgreSQL 9.4.8
**Repmgr Version** => repmgr 3.1.3 (PostgreSQL 9.4.8)
**I have configured the Pgpool in Master-Slave mode using Streaming replication.**
The setup is as shown in the below image:
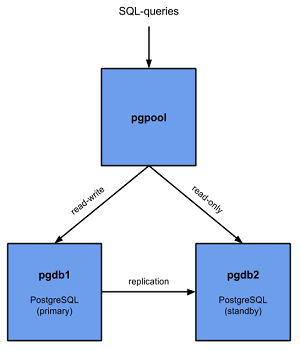 When I bring down the Master node(192.168.0.6), the automatic failover happens successfully and the Slave node(192.168.0.7) becomes the new Master node.
After failover, I have to recover the failed node(192.168.0.6) manually and sync it with the new Master node. Then register the node(192.168.0.6) as a new Standby node.
I want to automate the Recovery process of the failed node and add it to the cluster back.
The **pgpool.conf** file on the Pgpool node(192.168.0.4) contains parameter **recovery_1st_stage_command**. I have set the parameter **recovery_1st_stage_command = 'basebackup.sh'**. I have placed the script 'basebackup.sh' file on **both** the Postgresql nodes(192.168.0.6, 192.168.0.7) under the data directory **'/var/lib/pgsql/9.4/data'**. Also I have placed the script **'pgpool_remote_start'** on both the Postgresql nodes(192.168.0.6, 192.168.0.7) under the directory '/var/lib/pgsql/9.4/data'.
Also created the pgpool extension **"pgpool_recovery and pgpool_adm"** on both the database node.
After the failover is completed, the 'basebackup.sh' is not executed automatically. I have to run the command **'pcp_recovey_node'** manually on the **Pgpool node(192.168.0.4)** to recover the failed node(192.168.0.6).
How can I automate the execution of **pcp_recovery_node** command on the Pgpool node with out any manual intervention.
Scripts used by me as follows:
basebackup.sh script
-------------
#!/bin/bash
# first stage recovery
# $1 datadir
# $2 desthost
# $3 destdir
#as I'm using repmgr it's not necessary for me to know datadir(master) $1
RECOVERY_NODE=$2
CLUSTER_PATH=$3
#repmgr needs to know the master's ip
MASTERNODE=
When I bring down the Master node(192.168.0.6), the automatic failover happens successfully and the Slave node(192.168.0.7) becomes the new Master node.
After failover, I have to recover the failed node(192.168.0.6) manually and sync it with the new Master node. Then register the node(192.168.0.6) as a new Standby node.
I want to automate the Recovery process of the failed node and add it to the cluster back.
The **pgpool.conf** file on the Pgpool node(192.168.0.4) contains parameter **recovery_1st_stage_command**. I have set the parameter **recovery_1st_stage_command = 'basebackup.sh'**. I have placed the script 'basebackup.sh' file on **both** the Postgresql nodes(192.168.0.6, 192.168.0.7) under the data directory **'/var/lib/pgsql/9.4/data'**. Also I have placed the script **'pgpool_remote_start'** on both the Postgresql nodes(192.168.0.6, 192.168.0.7) under the directory '/var/lib/pgsql/9.4/data'.
Also created the pgpool extension **"pgpool_recovery and pgpool_adm"** on both the database node.
After the failover is completed, the 'basebackup.sh' is not executed automatically. I have to run the command **'pcp_recovey_node'** manually on the **Pgpool node(192.168.0.4)** to recover the failed node(192.168.0.6).
How can I automate the execution of **pcp_recovery_node** command on the Pgpool node with out any manual intervention.
Scripts used by me as follows:
basebackup.sh script
-------------
#!/bin/bash
# first stage recovery
# $1 datadir
# $2 desthost
# $3 destdir
#as I'm using repmgr it's not necessary for me to know datadir(master) $1
RECOVERY_NODE=$2
CLUSTER_PATH=$3
#repmgr needs to know the master's ip
MASTERNODE=
When I bring down the Master node(192.168.0.6), the automatic failover happens successfully and the Slave node(192.168.0.7) becomes the new Master node.
After failover, I have to recover the failed node(192.168.0.6) manually and sync it with the new Master node. Then register the node(192.168.0.6) as a new Standby node.
I want to automate the Recovery process of the failed node and add it to the cluster back.
The **pgpool.conf** file on the Pgpool node(192.168.0.4) contains parameter **recovery_1st_stage_command**. I have set the parameter **recovery_1st_stage_command = 'basebackup.sh'**. I have placed the script 'basebackup.sh' file on **both** the Postgresql nodes(192.168.0.6, 192.168.0.7) under the data directory **'/var/lib/pgsql/9.4/data'**. Also I have placed the script **'pgpool_remote_start'** on both the Postgresql nodes(192.168.0.6, 192.168.0.7) under the directory '/var/lib/pgsql/9.4/data'.
Also created the pgpool extension **"pgpool_recovery and pgpool_adm"** on both the database node.
After the failover is completed, the 'basebackup.sh' is not executed automatically. I have to run the command **'pcp_recovey_node'** manually on the **Pgpool node(192.168.0.4)** to recover the failed node(192.168.0.6).
How can I automate the execution of **pcp_recovery_node** command on the Pgpool node with out any manual intervention.
Scripts used by me as follows:
basebackup.sh script
-------------
#!/bin/bash
# first stage recovery
# $1 datadir
# $2 desthost
# $3 destdir
#as I'm using repmgr it's not necessary for me to know datadir(master) $1
RECOVERY_NODE=$2
CLUSTER_PATH=$3
#repmgr needs to know the master's ip
MASTERNODE=/sbin/ifconfig eth0 | grep inet | awk '{print $2}' | sed 's/addr://'
cmd1=ssh postgres@$RECOVERY_NODE "repmgr -D $CLUSTER_PATH --force standby clone $MASTERNODE"
echo $cmd1
## pgpool_remote_start script
#! /bin/sh
if [ $# -ne 2 ]
then
echo "pgpool_remote_start remote_host remote_datadir"
exit 1
fi
DEST=$1
DESTDIR=$2
PGCTL=/usr/pgsql-9.4/bin/pg_ctl
ssh -T $DEST $PGCTL -w -D $DESTDIR start 2>/dev/null 1>/dev/null /dev/null 1>/dev/null &1 | tee -a /tmp/pgpool_failover.log
Help me with the procedure to automate the recovery of the failed node.
Also let me know, for failover is it compulsory to use repmgr or we can do it without repmgr. Also specify any other method for failover without using Repmgr, its advantages and disadvantages over Repmgr.
Asked by yravi104
(21 rep)
Sep 8, 2016, 04:51 PM
Last activity: Jun 4, 2025, 03:08 AM
Last activity: Jun 4, 2025, 03:08 AM