Why does a subquery reduce the row estimate to 1?
26
votes
2
answers
1455
views
Consider the following contrived but simple query:
SELECT
ID
, CASE
WHEN ID 0
THEN (SELECT TOP 1 ID FROM X_OTHER_TABLE)
ELSE (SELECT TOP 1 ID FROM X_OTHER_TABLE_2)
END AS ID2
FROM X_HEAP;
I would expect the final row estimate for this query to be equal to the number of rows in the 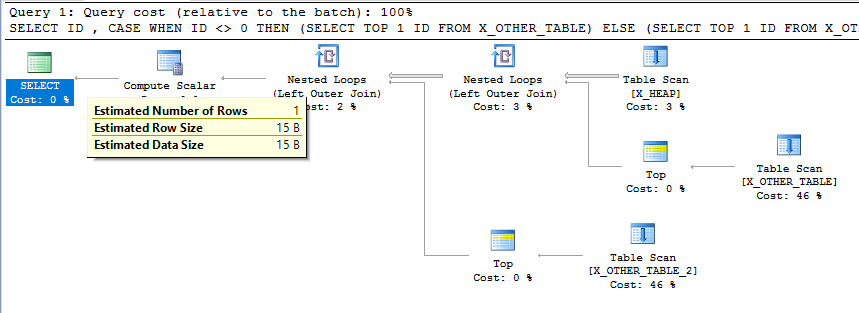 Why does this happen? What can I do about it?
It's very easy to reproduce this issue with the right syntax. Here is one set of table definitions that will do it:
CREATE TABLE dbo.X_HEAP (ID INT NOT NULL)
CREATE TABLE dbo.X_OTHER_TABLE (ID INT NOT NULL);
CREATE TABLE dbo.X_OTHER_TABLE_2 (ID INT NOT NULL);
INSERT INTO dbo.X_HEAP WITH (TABLOCK)
SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM master..spt_values;
CREATE STATISTICS X_HEAP__ID ON X_HEAP (ID) WITH FULLSCAN;
db fiddle link .
Why does this happen? What can I do about it?
It's very easy to reproduce this issue with the right syntax. Here is one set of table definitions that will do it:
CREATE TABLE dbo.X_HEAP (ID INT NOT NULL)
CREATE TABLE dbo.X_OTHER_TABLE (ID INT NOT NULL);
CREATE TABLE dbo.X_OTHER_TABLE_2 (ID INT NOT NULL);
INSERT INTO dbo.X_HEAP WITH (TABLOCK)
SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM master..spt_values;
CREATE STATISTICS X_HEAP__ID ON X_HEAP (ID) WITH FULLSCAN;
db fiddle link .
X_HEAP table. Whatever I'm doing in the subquery shouldn't matter for the row estimate because it cannot filter out any rows. However, on SQL Server 2016 I see the row estimate reduced to 1 because of the subquery:
Why does this happen? What can I do about it?
It's very easy to reproduce this issue with the right syntax. Here is one set of table definitions that will do it:
CREATE TABLE dbo.X_HEAP (ID INT NOT NULL)
CREATE TABLE dbo.X_OTHER_TABLE (ID INT NOT NULL);
CREATE TABLE dbo.X_OTHER_TABLE_2 (ID INT NOT NULL);
INSERT INTO dbo.X_HEAP WITH (TABLOCK)
SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM master..spt_values;
CREATE STATISTICS X_HEAP__ID ON X_HEAP (ID) WITH FULLSCAN;
db fiddle link .
Asked by Joe Obbish
(32976 rep)
Apr 21, 2017, 03:33 PM
Last activity: Nov 24, 2024, 01:24 PM
Last activity: Nov 24, 2024, 01:24 PM