Couldn't find a newbie forum; hope this is in the right place.
In my quest to learn more about databases, analytics, and creating service APIs to work with them, I decided to scrape an online archive of Jeopardy data and plan to reconstruct the data into a functional db. Pretty sure this has been done before, but learning is the primary objective here :)
I'd like to get the data structured so I can run some advanced statistics on it. To do so, I'll need to query things like a player's score at any given point in the game, see who picked which clues and in what order, identify (and grade) players' wagering on daily doubles & Final Jeopardy, etc. If all goes to plan, it would be neat to expose this via public API so others can play with it too.
There's a decent amount of data here, though it's not very big compared to enterprise dbs:
- 6000 distinct games
- ~60 clues per game, so ~360k total unique clues.
- 12000 players, which includes duplicates (ex: Ken1 , Ken2 , Ken3 )
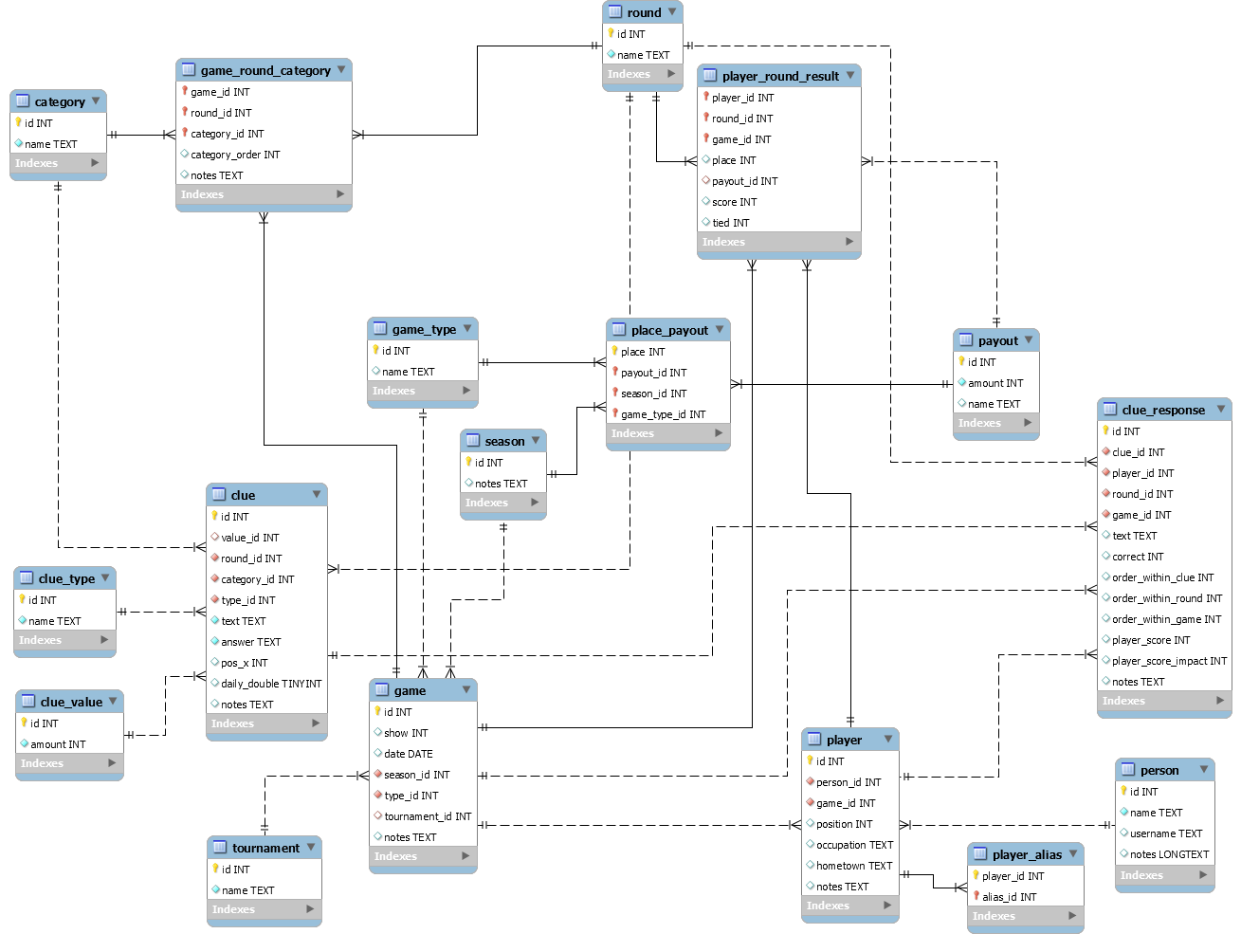
Below is the latest draft of my data model ( ,
,  ) based on the data available from j-archive, the general structure of Jeopardy games, and my limited understanding of database design. Appreciate any feedback -- especially on the clue_response table, which is the only table with transactional data.
) based on the data available from j-archive, the general structure of Jeopardy games, and my limited understanding of database design. Appreciate any feedback -- especially on the clue_response table, which is the only table with transactional data.
 Data is currently stored in an sqlite3 db. Will probably migrate it to MySQL once I settle on a structure.
Data is currently stored in an sqlite3 db. Will probably migrate it to MySQL once I settle on a structure.
, ) based on the data available from j-archive, the general structure of Jeopardy games, and my limited understanding of database design. Appreciate any feedback -- especially on the clue_response table, which is the only table with transactional data.
Data is currently stored in an sqlite3 db. Will probably migrate it to MySQL once I settle on a structure.
Asked by brystmar
(11 rep)
Jan 23, 2018, 11:18 PM
Last activity: Jan 24, 2018, 06:38 PM
Last activity: Jan 24, 2018, 06:38 PM