PostgreSQL query suddenly very slow after new column addition
1
vote
1
answer
1982
views
I have a query that's performing terribly after adding a new column. Here's the slow version:
SELECT COUNT(*)
FROM activities
INNER JOIN "users" ON "users"."id" = "activities"."user_id" AND "users"."api_user_for" IS NULL
WHERE "activities"."department_id" = 123456789
AND "users"."api_user_for" IS NULL
The new column is the 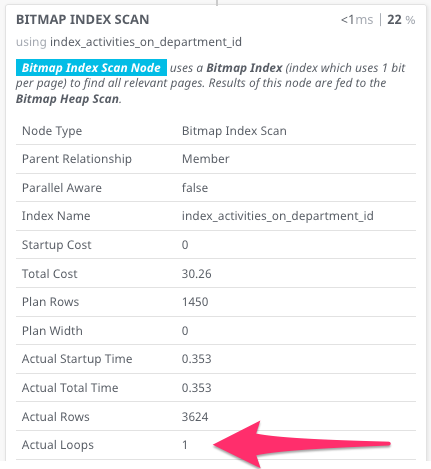
 The "fast query" in this case is the same query with one of the (unnecessarily duplicated)
The "fast query" in this case is the same query with one of the (unnecessarily duplicated)
api_user_for column. It's a nullable string type. The SQL itself is generated from Ruby on Rails. We've added a "default scope", and that's why the api_user_for seems to appear twice in the query (on the join and in the where clause).
If I remove *either one* of those api_user_for checks, the query returns to its former speed. By including them both, however, the query moves from taking less than 100ms to taking close to 10 seconds.
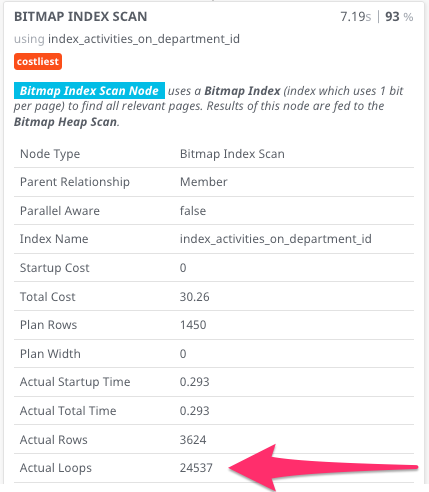
I've compared the query plans using PEV, and here's the fast and slow queries compared:
The "fast query" in this case is the same query with one of the (unnecessarily duplicated) api_user_for checks removed. For example, both of these queries are fast:
SELECT COUNT(*)
FROM activities
INNER JOIN "users" ON "users"."id" = "activities"."user_id"
WHERE "activities"."department_id" = 123456789
AND "users"."api_user_for" IS NULL
and
SELECT COUNT(*)
FROM activities
INNER JOIN "users" ON "users"."id" = "activities"."user_id" AND "users"."api_user_for" IS NULL
WHERE "activities"."department_id" = 123456789
Obviously there's a huge disparity in the number of loops performed, but why are these loops taking place? The scan seems otherwise very similar.
I would love some insight into what could be going on as this fairly innocuous query is now bringing performance to its knees!
Postgres Version: 9.6.8
Asked by aardvarkk
(235 rep)
Nov 27, 2018, 11:28 PM
Last activity: Nov 22, 2020, 09:04 PM
Last activity: Nov 22, 2020, 09:04 PM