Bulk SQL INSERT into Azure SQL Database using spark causes blocking/contention?
0
votes
1
answer
969
views
I am running the following code using microsoft's sql sparkconnector to write a 1-2 Billion dataframe into Azure SQL Database.
df.write \
.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", secrets.db.url) \
.option("dbtable", 'tableName') \
.option("user", secrets.db.user) \
.option("password", secrets.db.password) \
.option("batchsize", 1048576) \
.option("schemaCheckEnabled", "false") \
.option("BulkCopyTimeout", 3600) \
.save()
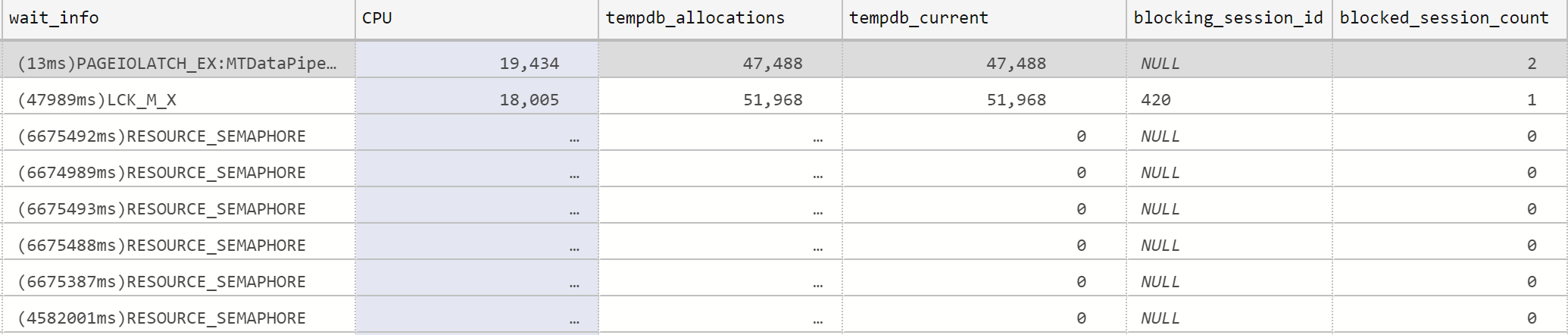 EXEC sp_WhoIsActive
@find_block_leaders = 1,
@sort_order = '[blocked_session_count] DESC'
The wait_info column's value is
EXEC sp_WhoIsActive
@find_block_leaders = 1,
@sort_order = '[blocked_session_count] DESC'
The wait_info column's value is
EXEC sp_WhoIsActive
@find_block_leaders = 1,
@sort_order = '[blocked_session_count] DESC'
The wait_info column's value is Resource_Semaphore.
Configs:
My dataframe is partitioned over 2100 partitions on a cluster of 900 cores
My database is 14 vcores in General Purpose tier on Azure.
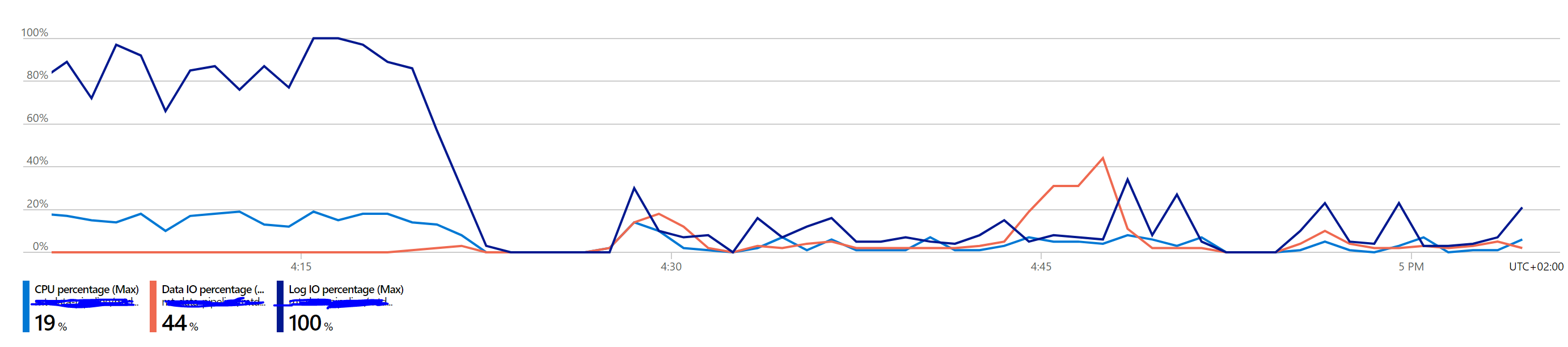
My query is incredibly slow because of this blocking. It's almost like it's running one bulk insert from my cluster at a time. Any suggestions on what to change to speed it up? or any insights into why it's blocking?
Asked by Youssef Fares
Dec 22, 2020, 03:35 PM
Last activity: Mar 11, 2025, 07:09 PM
Last activity: Mar 11, 2025, 07:09 PM