Best practices for large JOINs - Warehouse or External Compute (e.g. Spark)
2
votes
1
answer
677
views
I am working on a problem that requires a very large join. The JOIN itself is pretty straightforward but the amount of data I am processing is very large. I am wondering for very large JOINs, is there a preferred type of technology. For example, is it more effective to a Data Warehouse (like Snowflake) or in some other MPP system like Spark?
To make the problem more concrete I created a hypothetical problem similar to my actual problem. Assume I have a table that looks like this:
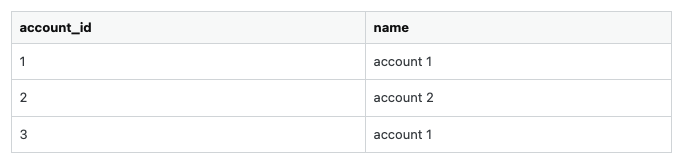 I am working on some logic that requires account pairs that have the same name. To find pairs of accounts with the same account I can easily do something like this:
I am working on some logic that requires account pairs that have the same name. To find pairs of accounts with the same account I can easily do something like this:
I am working on some logic that requires account pairs that have the same name. To find pairs of accounts with the same account I can easily do something like this:
SELECT
account1.name,
account2.name
FROM accounts as account1
JOIN accounts as account2 ON account1.name = account2.name AND account1.acount_id != account2.acount_id
Asked by Arthur Putnam
(553 rep)
Feb 24, 2022, 09:06 PM
Last activity: Dec 18, 2024, 12:01 PM
Last activity: Dec 18, 2024, 12:01 PM