How repeatable read isolation level and others are implemented in distributed/replicated databases?
0
votes
1
answer
224
views
I'm studying distributed systems/DBs and I'm struggling understanding isolation levels when we talk about distributed systems.
Avoiding problems like dirty read, non-repeatable read, phantom reads, write-skew, etc. when we have a single DB is pretty straightforward with the introduction of optimistic / pessimistic concurrency control algorithms.
Nevertheless, I'm really not understanding how the same problems are avoided when we deal with distributed systems.
## Example
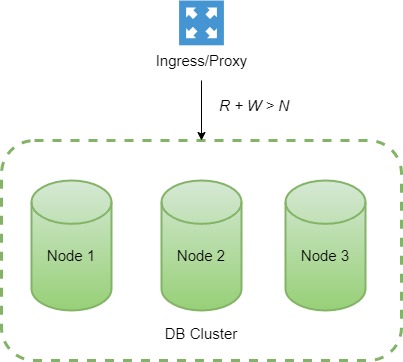 Let's say that we have three total nodes (*N = 3*) for our DB and we want strong consistency for some reason (*R = 2* and *W = 2*, so *R + W > N*).
Let' say now that we have two transactions: T1, T2.
- T1:
Let's say that we have three total nodes (*N = 3*) for our DB and we want strong consistency for some reason (*R = 2* and *W = 2*, so *R + W > N*).
Let' say now that we have two transactions: T1, T2.
- T1:
Let's say that we have three total nodes (*N = 3*) for our DB and we want strong consistency for some reason (*R = 2* and *W = 2*, so *R + W > N*).
Let' say now that we have two transactions: T1, T2.
- T1:
SELECT * FROM X WHERE X.field = 'something'
... DO WORK ...
SELECT * FROM X WHERE X.field = 'something'INSERT INTO X VALUES(..,..,..) -- impact T1 search criteria
Asked by Dev
(1 rep)
Aug 14, 2022, 04:20 PM
Last activity: Jun 11, 2025, 07:07 PM
Last activity: Jun 11, 2025, 07:07 PM