Optimising a recursive SQL query that processes several million records in BQ
0
votes
0
answers
253
views
I need help optimizing a recursive SQL query in BQ.
I have hierarchical data stored in a table as parent-child relationships, i.e
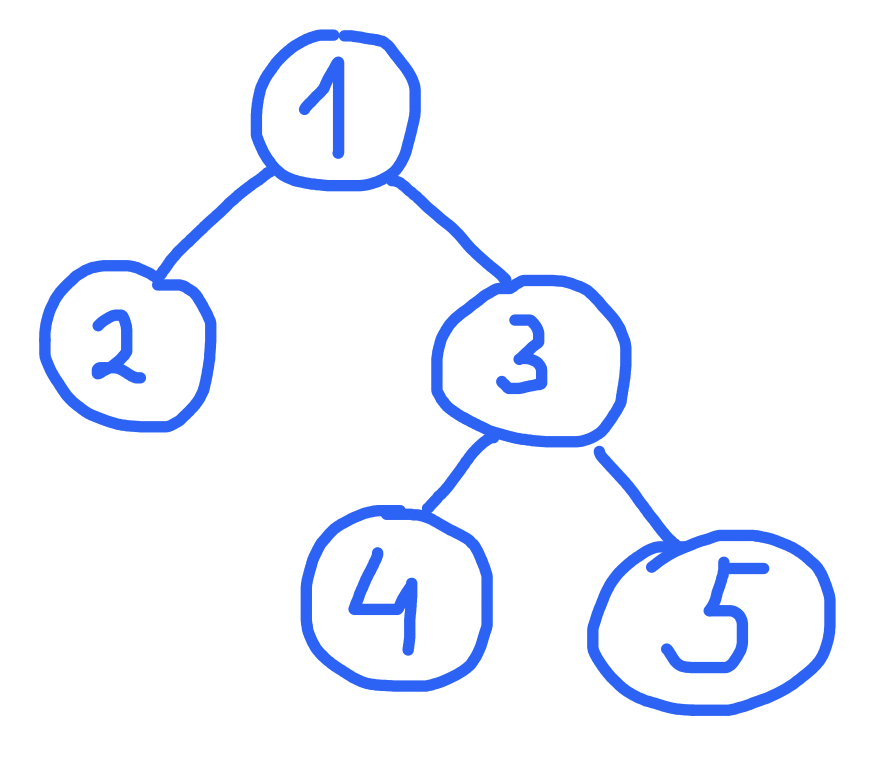 will be stored as
| parent_item_id | child_item_id |
| ---------------| --------------|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 3 | 4 |
| 3 | 5 |
| ... | ... |
when
will be stored as
| parent_item_id | child_item_id |
| ---------------| --------------|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 3 | 4 |
| 3 | 5 |
| ... | ... |
when 
will be stored as
| parent_item_id | child_item_id |
| ---------------| --------------|
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 3 | 4 |
| 3 | 5 |
| ... | ... |
when parent_item_id = child_item_id it means that this is a root node. I need to produce the following resulting table from the parent-child mapping:
| root_id | parent_item_id | child_item_id | level |
| --------| ---------------| --------------| ------ |
| 1 | 1 | 1 | 0 |
| 1 | 1 | 2 | 1 |
| 1 | 1 | 3 | 1 |
| 1 | 3 | 4 | 2 |
| 1 | 3 | 5 | 2 |
| ... | ... | ... | ... |
To do that I first prepared separate tables for parents and children:
-- parents
SELECT * FROM parent_child_mapping WHERE parent_item_id = child_item_id;-- children
SELECT * FROM parent_child_mapping WHERE parent_item_id child_item_id;-- root nodes
SELECT p.* FROM parents p
LEFT JOIN children c
ON
p.parent_item_id = c.child_item_id
WHERE
c.child_item_id IS NULLSELECT
i.root_id,
i.parent_item_id,
i.child_item_id
0 AS level
FROM roots i
UNION ALL
SELECT
t.root_id,
t.parent_item_id,
t.child_item_id,
t.level + 1,
FROM children AS i
INNER JOIN objects_tree AS t
ON
t.child_item_id = i.parent_item_idWITH RECURSIVE
parents AS (
SELECT * FROM parent_child_mapping WHERE parent_item_id = child_item_id;
),
children AS (
SELECT * FROM parent_child_mapping WHERE parent_item_id child_item_id;
),
roots AS (
SELECT p.* FROM parents p
LEFT JOIN children c
ON
p.parent_item_id = c.child_item_id
WHERE
c.child_item_id IS NULL
),
objects_tree AS (
SELECT
i.root_id,
i.parent_item_id,
i.child_item_id
0 AS level
FROM roots i
UNION ALL
SELECT
t.root_id,
t.parent_item_id,
t.child_item_id,
t.level + 1,
FROM children AS i
INNER JOIN objects_tree AS t
ON
t.child_item_id = i.parent_item_id
)
SELECT * FROM objects_tree...
FROM children AS i
INNER JOIN objects_tree AS t
ON
t.child_item_id = i.parent_item_id
Asked by Roman Dryndik
(101 rep)
Jan 24, 2023, 08:43 PM
Last activity: Jan 25, 2023, 10:41 AM
Last activity: Jan 25, 2023, 10:41 AM