AWS Aurora Mysql seemingly not picking PRIMARY or secondary index
4
votes
1
answer
1485
views
Relevant System Info:
Aurora Mysql 8.0.mysql_aurora.3.03
rg6.xl instances (1 writer, 2 read replicas)
Total size:5.5TB (all databases combined, or just looking at the most recent Snapshot)
I have been working on migrating mariadb databases deprecated tokudb engine to RDS Aurora Mysql. With some fine tuning of the parameters in RDS, there has been one behavior I cannot understand.
**Scenario**
The main database houses tables created by each year, so lets use TABLE_2023 as an example. In this table, there are two indexes; the primary and the secondary index. PRIMARY index(ID, DATE) and Secondary(DATE). If I take a query like the following, and thrown an  select count(*) on this year's table brings back 1809962901 rows.
**CREATE TABLE Results**
select count(*) on this year's table brings back 1809962901 rows.
**CREATE TABLE Results**
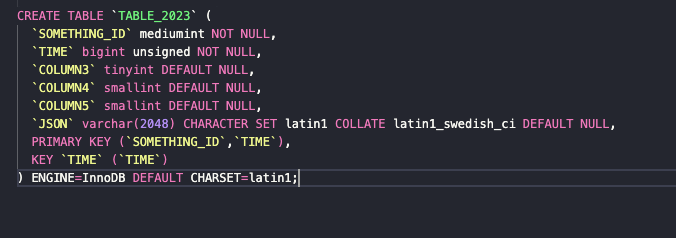 CREATE TABLE
CREATE TABLE  Query Results
1822 rows in set (52.513 sec)
So, again, same behavior. Before I reverse the Primary Key order (as I did before), waiting to see response from Rolando for any further suggestions.
**Update as of 05/16/2023**
I have another meeting planned with AWS,but this time with an Aurora Mysql Specialist. Before I have the meeting, they suggested to turn off aurora_parallel_query.
Upon doing this, I ran the same example query and was shocked to see the results. The Explain results showed
|id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra|
|--|-----------|-----|----------|----|-------------|---|-------|---|----|--------|-----|
|1|SIMPLE|TABLE_2023||range|PRIMARY,time_Something_ID|PRIMARY|11||1823|100.0|Using where|
And the query itself, when ran, completed extremely quickly.
Query Results
1822 rows in set (52.513 sec)
So, again, same behavior. Before I reverse the Primary Key order (as I did before), waiting to see response from Rolando for any further suggestions.
**Update as of 05/16/2023**
I have another meeting planned with AWS,but this time with an Aurora Mysql Specialist. Before I have the meeting, they suggested to turn off aurora_parallel_query.
Upon doing this, I ran the same example query and was shocked to see the results. The Explain results showed
|id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra|
|--|-----------|-----|----------|----|-------------|---|-------|---|----|--------|-----|
|1|SIMPLE|TABLE_2023||range|PRIMARY,time_Something_ID|PRIMARY|11||1823|100.0|Using where|
And the query itself, when ran, completed extremely quickly.
 However, before I write this off as the answer, I am curious to why this is the solution. Amazon markets Aurora Parallel Query as a benefit for moving to Aurora, so my use case must not benefit from this. I will post the details of the meeting here when I have them.
**Update as of 05/25/2023**
Same behavior with 3.03.1. Sending AWS a snapshot of our TABLE_2023 with a bug report.
**Update as of 06/12/2023**
AWS internally identified the "bug" and the fix is set to be released in the public versions of 3.04.0 and 3.03.2. These are projected to come out at the end of this quarter, or the beginning of next quarter.
However, before I write this off as the answer, I am curious to why this is the solution. Amazon markets Aurora Parallel Query as a benefit for moving to Aurora, so my use case must not benefit from this. I will post the details of the meeting here when I have them.
**Update as of 05/25/2023**
Same behavior with 3.03.1. Sending AWS a snapshot of our TABLE_2023 with a bug report.
**Update as of 06/12/2023**
AWS internally identified the "bug" and the fix is set to be released in the public versions of 3.04.0 and 3.03.2. These are projected to come out at the end of this quarter, or the beginning of next quarter.
TABLE_2023 (
SOMETHING_ID mediumint NOT NULL,
TIME bigint unsigned NOT NULL,
COLUMN3 tinyint DEFAULT NULL,
COLUMN4 smallint DEFAULT NULL,
COLUMN5 smallint DEFAULT NULL,
JSON varchar(2048) CHARACTER SET latin1 COLLATE latin1_swedish_ci DEFAULT NULL,
PRIMARY KEY (SOMETHING_ID,TIME),
KEY TIME (TIME)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
**API Behaviors**
Users that use the api can request a range of data. However, the query behavior is almost always asking the database for time series data for either an single ID or multiple IDs for the same time series. Currently, the code behind the API uses the "TIME>='' and TIME<=''" for a time range, not BETWEEN. Nor does it use "ID='1'" for a single station, but rather "in". I have recommended the developers to change the code to use "=" if one station is used, to avoid the table scan.
**Final Thoughts**
Can we get away with forcing the index we want the query to use? Of course. But the behavior we are seeing with Aurora Mysql not being able to pick the index without being forced to bothers me. Especially when I do the same queries against our current databases environment (which will use an index, regardless of being forced). The only time I am able to get an index used is by using simple queries;
EXPLAIN select * from TABLE_2023 where SOMETHING_ID in (1206); --index PRIMARY "used"
EXPLAIN select * from TABLE_2023 where SOMETHING_ID = '1206'; --index PRIMARY "used"
EXPLAIN SELECT * FROM TABLE_2023 where TIME = '202304170000'; --index TIME "used"
**Update as of 05/01/2023**
I dropped the year table (2023) and reimported all the data from our source database using DMS (again). After this was done, I added the secondary index (TIME) since DMS will usually only grab the primary index. After this was done, I took the same example query and still my EXPLAIN results show no usage of an index.
https://docs.aws.amazon.com/dms/latest/userguide/CHAP_BestPractices.html
I came across this document when reviewing the methods I was loading data into tables. Turns out AWS recommends dropping Primary Index if doing a full table load. Going to give this a try and load the data, then re-add just the PRIMARY index.
**Update as of 05/02/2023**
After creating a new table w/o the PRIMARY index and secondary index, I loaded the data into the table via DMS. Once completed, I waited 6+ hours for the PRIMARY key index to create. Unfortunately, the behavior still exists. However, I do have a scheduled call with AWS reps that I hope to get an answer for this behavior. Once an answer is vetted, I will post here.
**Update as of 05/05/2023**
After meeting with AWS account managers, they will be relaying technical information to their engineers to take a look at. In the meantime, I conducted a few more tests:
*Scenario 1:*
Create table with primary key index only
Load 38,000 rows, run 'EXPLAIN' with the example query-primary index would have been used.
*Scenario 2:*
Create table with primary key index only
Load 23 million rows, run 'EXPLAIN' with the example query-primary index identified, but not used
*Scenario 3:*
Drop primary index in table from Scenario 2
Re-add primary index, run 'EXPLAIN' with the example query-primary index identified, but not used
*Scenario 4:*
Create table without primary key index
Load 23 million rows, add primary key index, run 'EXPLAIN' with the example query-primary index identified, but not used
*Scenario* 5:
Create table without primary key index
Load 38,000 rows, add primary key, run 'EXPLAIN' with example query-primary index identified and used
*Scenario 6:*
Create table without primary key index
Load around 12 million rows, add primary key, run 'EXPLAIN' with example query-primary index identified but not used.
**Update as of 05/08/2023**
Tried suggested answer, same behavior. Ended up doing the following but AWS Aurora MySQL behaved the same
ALTER TABLE TABLE_2023
ADD PRIMARY KEY (SOMETHING_ID,TIME),
ADD UNIQUE KEY TIME_SOMETHING_ID (TIME,SOMETHING_ID);
**Update as of 05/10/2023**
As suggested Rolando, I dropped the TIME index and added the following
ALTER TABLE TABLE_2023
ADD UNIQUE INDEX TIME_SOMETHING_ID (TIME,SOMETHING_ID);
I then ran the example query in the beginning of this post. Here are the results:
EXPLAIN
Query Results
1822 rows in set (52.513 sec)
So, again, same behavior. Before I reverse the Primary Key order (as I did before), waiting to see response from Rolando for any further suggestions.
**Update as of 05/16/2023**
I have another meeting planned with AWS,but this time with an Aurora Mysql Specialist. Before I have the meeting, they suggested to turn off aurora_parallel_query.
Upon doing this, I ran the same example query and was shocked to see the results. The Explain results showed
|id|select_type|table|partitions|type|possible_keys|key|key_len|ref|rows|filtered|Extra|
|--|-----------|-----|----------|----|-------------|---|-------|---|----|--------|-----|
|1|SIMPLE|TABLE_2023||range|PRIMARY,time_Something_ID|PRIMARY|11||1823|100.0|Using where|
And the query itself, when ran, completed extremely quickly.
However, before I write this off as the answer, I am curious to why this is the solution. Amazon markets Aurora Parallel Query as a benefit for moving to Aurora, so my use case must not benefit from this. I will post the details of the meeting here when I have them.
**Update as of 05/25/2023**
Same behavior with 3.03.1. Sending AWS a snapshot of our TABLE_2023 with a bug report.
**Update as of 06/12/2023**
AWS internally identified the "bug" and the fix is set to be released in the public versions of 3.04.0 and 3.03.2. These are projected to come out at the end of this quarter, or the beginning of next quarter.
Asked by Randoneering
(135 rep)
Apr 27, 2023, 09:34 PM
Last activity: Mar 18, 2025, 07:03 PM
Last activity: Mar 18, 2025, 07:03 PM