Why does MariaDB execution time is doubled for the same query (LOAD DATA INFILE)?
0
votes
1
answer
115
views
I observed a strange behaviour regarding the execution time of a query to import a CSV file in an empty table created beforehand. The query execution time to import the file increases while repeating the import.
I meet this behaviour while importing 10 times the same medium CSV file (0.6 GB, 6 columns, 8 million rows) using TRUNCATE then LOAD DATA INFILE, repeated 10 times within one MariaDB connection.
On the first iteration, the CSV import takes 40 seconds, then about 50 seconds on the second iteration, and from the third to the 10th iteration, the execution time reaches a plateau at 85 +/- 5 s.
I performed the test twice :
- on the mariadb shell (alias "mysql" on GNU Linux)
- on python3 using mysql.connector
And I get the same result, i.e. an execution time that doubles (see figure)...
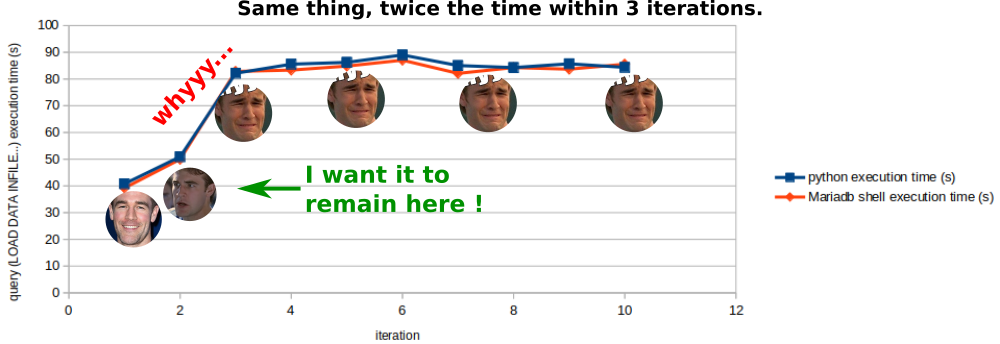 **• What could explain (or avoid) the execution time being doubled between the first and the third iteration ?**
Steps to reproduce the behaviour :
1. Initiation : create (just once) the empty table with a generated primary key (idRow) :
CREATE TABLE
**• What could explain (or avoid) the execution time being doubled between the first and the third iteration ?**
Steps to reproduce the behaviour :
1. Initiation : create (just once) the empty table with a generated primary key (idRow) :
CREATE TABLE
**• What could explain (or avoid) the execution time being doubled between the first and the third iteration ?**
Steps to reproduce the behaviour :
1. Initiation : create (just once) the empty table with a generated primary key (idRow) :
CREATE TABLE myTable (col1 VARCHAR(14), col2 VARCHAR(14), col3 VARCHAR(10), col4 VARCHAR(5), col5 VARCHAR(5), col6 VARCHAR(19), idRow INT NOT NULL AUTO_INCREMENT, PRIMARY KEY (idRow));
2. Repeat steps A. and B. 10 times and collect the execution time of step B. for each iteration :
A. Empty the table using TRUNCATE :
TRUNCATE TABLE myTable;
B. Then import a 0.6 GB-large CSV file of 8 million rows and 6 columns :
LOAD DATA INFILE "/myData/myFile.csv" INTO TABLE myTable FIELDS TERMINATED BY "," LINES TERMINATED BY "\n" IGNORE 1 ROWS (col1, col2, col3, col4, col5, col6) SET idRow=NULL;
Any help to understand this phenomenon would be welcome, dont hesitate to ask for more info.
*Why do I do this ?
The goal is to build a procedure to measure robustly the statistics of the execution time of any query, and how much it fluctuates determines the number of iterations one needs to get a relevant sample size. I was surprised that any query could fluctuate of 100% in execution time.*
Giorgio
MariaDB server :
- OS : Linux Mint 20
- mariadb version : 10.3.38-MariaDB-0ubuntu0.20.04.1-log
- innodb version : 10.3.38
[update] I made other interesting observations :
(i) : On the same OS session (i.e. no reboot) : closing the mariadb connection, or restarting the mariadb service (systemctl restart mariadb) does not prevent the 2nd iteration getting slower (50 to 87 s) than the first.
(ii) : After rebooting the OS, the B query gets fast again (40 sec).
Asked by GiorgioAbitbolo
(1 rep)
Jun 8, 2023, 07:40 PM
Last activity: Jun 10, 2023, 06:57 AM
Last activity: Jun 10, 2023, 06:57 AM