PostgreSQL query optimization over multiple tables with moderately large data
0
votes
0
answers
223
views
We have a data structure in PostgreSQL 16 which is moderately complex, I have a simplified diagram showing the join columns here:
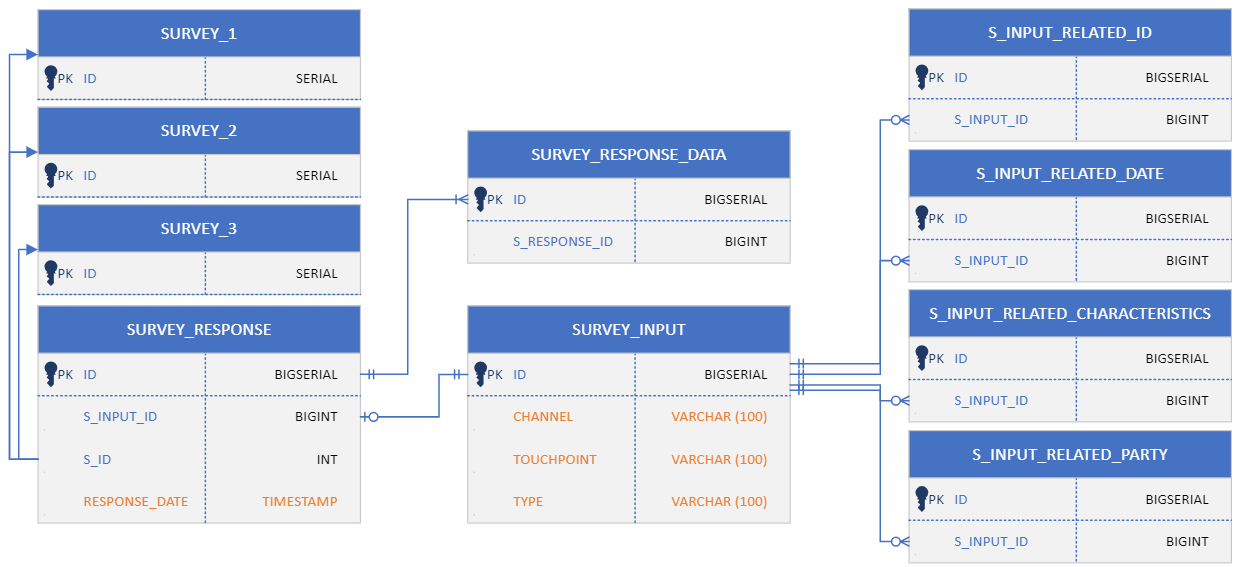 The 3 SURVEY tables on the top left are exceptions because they are not joined with foreign key, rather we have a SURVEY_ID column which can point to the ID of any of this 3 SURVEY tables (this is due to historic reasons, another column in the SURVEY_INPUT table decides which of these 3 to use). SURVEY_INPUT table also has the same SURVEY_ID column, which is not present here.
Here are the row counts:
- SURVEY_INPUT: 160K
- SURVEY_INPUT_RELATED_ID: 110K
- SURVEY_INPUT_RELATED_DATE: 68K
- SURVEY_INPUT_RELATED_CHARACTERISTICS: 355K
- SURVEY_INPUT_RELATED_PARTY: 400K
- SURVEY_RESPONSE: 29K
- SURVEY_RESPONSE_DATA: 76K
When these tables were designed there were no such requirements, but now we are looking at some specific reports which are ungodly slow. It must be filtered by the highlighted columns. At the moment we have maybe 1 week's data in these tables and the report can take 10 minutes to load, and we need to support 3 month's data... What I'm basically looking for as step 1 is to whether focus on the application side queries or the database performance... In our original implementation some entity relationships were eager in JPA, some were lazy, which resulted in lots and lots of simple and quick queries being launched, which ultimately resulted in the long execution. Now the application developer has did some magic, set everything to be eager and now JPA created a monster query to get all the data with all the filtering in a single step, as a huge cross join. This is now faster, but still it can take anywhere from 3 to 6 minutes, depending on selected time range. I tried to work on this large query as well, modified it a bit and added some indexes on the highlighted colors as well as all join columns, but had minimal impact. Here is a link to my current progress on the query, this version with these parameters took 00:02:59.990 to run and resulted in 209450 rows:
https://explain.depesz.com/s/ROVz
It says the sorting in step 6 is using disk space due to not enough work mem, but even if I remove the ORDER BY completely the query is the same speed, or even a few seconds slower.
The 3 SURVEY tables on the top left are exceptions because they are not joined with foreign key, rather we have a SURVEY_ID column which can point to the ID of any of this 3 SURVEY tables (this is due to historic reasons, another column in the SURVEY_INPUT table decides which of these 3 to use). SURVEY_INPUT table also has the same SURVEY_ID column, which is not present here.
Here are the row counts:
- SURVEY_INPUT: 160K
- SURVEY_INPUT_RELATED_ID: 110K
- SURVEY_INPUT_RELATED_DATE: 68K
- SURVEY_INPUT_RELATED_CHARACTERISTICS: 355K
- SURVEY_INPUT_RELATED_PARTY: 400K
- SURVEY_RESPONSE: 29K
- SURVEY_RESPONSE_DATA: 76K
When these tables were designed there were no such requirements, but now we are looking at some specific reports which are ungodly slow. It must be filtered by the highlighted columns. At the moment we have maybe 1 week's data in these tables and the report can take 10 minutes to load, and we need to support 3 month's data... What I'm basically looking for as step 1 is to whether focus on the application side queries or the database performance... In our original implementation some entity relationships were eager in JPA, some were lazy, which resulted in lots and lots of simple and quick queries being launched, which ultimately resulted in the long execution. Now the application developer has did some magic, set everything to be eager and now JPA created a monster query to get all the data with all the filtering in a single step, as a huge cross join. This is now faster, but still it can take anywhere from 3 to 6 minutes, depending on selected time range. I tried to work on this large query as well, modified it a bit and added some indexes on the highlighted colors as well as all join columns, but had minimal impact. Here is a link to my current progress on the query, this version with these parameters took 00:02:59.990 to run and resulted in 209450 rows:
https://explain.depesz.com/s/ROVz
It says the sorting in step 6 is using disk space due to not enough work mem, but even if I remove the ORDER BY completely the query is the same speed, or even a few seconds slower.
The 3 SURVEY tables on the top left are exceptions because they are not joined with foreign key, rather we have a SURVEY_ID column which can point to the ID of any of this 3 SURVEY tables (this is due to historic reasons, another column in the SURVEY_INPUT table decides which of these 3 to use). SURVEY_INPUT table also has the same SURVEY_ID column, which is not present here.
Here are the row counts:
- SURVEY_INPUT: 160K
- SURVEY_INPUT_RELATED_ID: 110K
- SURVEY_INPUT_RELATED_DATE: 68K
- SURVEY_INPUT_RELATED_CHARACTERISTICS: 355K
- SURVEY_INPUT_RELATED_PARTY: 400K
- SURVEY_RESPONSE: 29K
- SURVEY_RESPONSE_DATA: 76K
When these tables were designed there were no such requirements, but now we are looking at some specific reports which are ungodly slow. It must be filtered by the highlighted columns. At the moment we have maybe 1 week's data in these tables and the report can take 10 minutes to load, and we need to support 3 month's data... What I'm basically looking for as step 1 is to whether focus on the application side queries or the database performance... In our original implementation some entity relationships were eager in JPA, some were lazy, which resulted in lots and lots of simple and quick queries being launched, which ultimately resulted in the long execution. Now the application developer has did some magic, set everything to be eager and now JPA created a monster query to get all the data with all the filtering in a single step, as a huge cross join. This is now faster, but still it can take anywhere from 3 to 6 minutes, depending on selected time range. I tried to work on this large query as well, modified it a bit and added some indexes on the highlighted colors as well as all join columns, but had minimal impact. Here is a link to my current progress on the query, this version with these parameters took 00:02:59.990 to run and resulted in 209450 rows:
https://explain.depesz.com/s/ROVz
It says the sorting in step 6 is using disk space due to not enough work mem, but even if I remove the ORDER BY completely the query is the same speed, or even a few seconds slower.
Asked by Gábor Major
(163 rep)
Jun 6, 2024, 02:05 PM