Oracle alert.log "Thread 1 cannot allocate new log" on AWS RDS
0
votes
1
answer
258
views
I migrated from an on-premise Oracle XE to Amazon RDS. It's running on a T3.medium server with gp3 storage (200 GB/12000 IOPS).
Almost every fifth minute the alert.log says like this:
"Thread 1 cannot allocate new log, sequence 10209
Checkpoint not complete"
3-4 seconds after that it logs another message:
"Thread 1 advanced to log sequence 10209 (LGWR switch), current SCN: 472780758"
And immediately after that:
"ARC1 (PID:6427): Archived Log entry 10205 added for B-1189761742.T-1.S-10208 ID 0x7efecf3c1c4d LAD:1 [krse.c:4934]"
Like this:
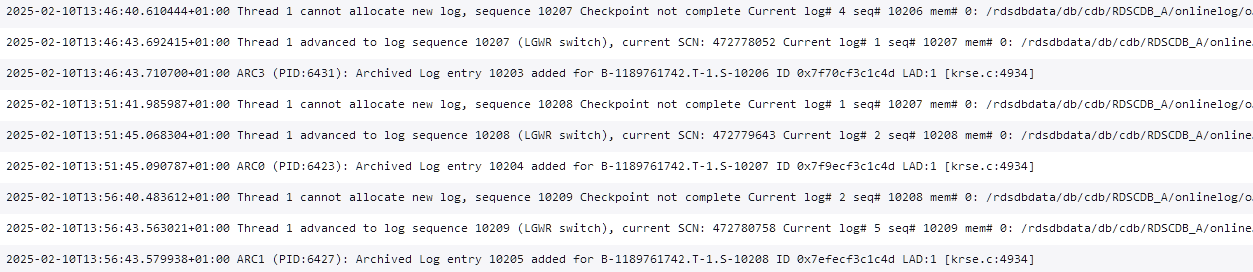 Reading about the first message ("cannot allocate new log") it seems as a "bad" message. The typical advice is to increase the redo log file size. So I added 4 log files, each 512 Mb. The advice was to remove the old log (128 Mb each) files but they are almost always "ACTIVE" so I have just managed to remove 1. This is the current status:
Reading about the first message ("cannot allocate new log") it seems as a "bad" message. The typical advice is to increase the redo log file size. So I added 4 log files, each 512 Mb. The advice was to remove the old log (128 Mb each) files but they are almost always "ACTIVE" so I have just managed to remove 1. This is the current status:
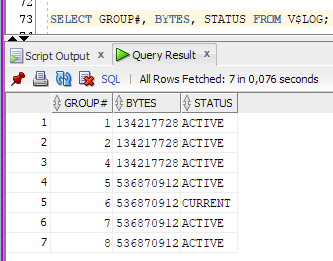 ... and I still get the error message in alert.log.
The parameter archive_lag_target is set to 300 (5 minutes), so I guess that's why it switches log file every five minutes. (I don't think I can change that setting in RDS.)
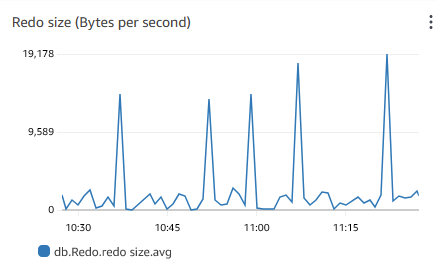
Looking at the disk operations in AWS doesn't imply that the disk is under too heavy load:
... and I still get the error message in alert.log.
The parameter archive_lag_target is set to 300 (5 minutes), so I guess that's why it switches log file every five minutes. (I don't think I can change that setting in RDS.)
Looking at the disk operations in AWS doesn't imply that the disk is under too heavy load:
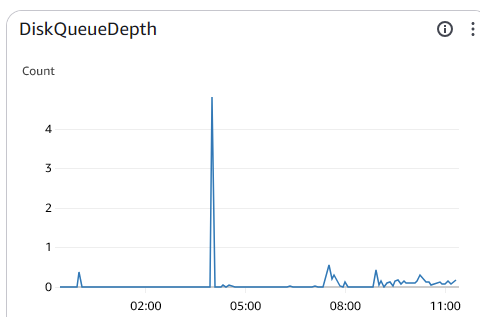
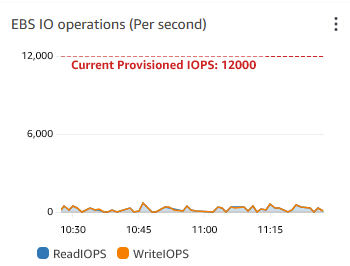
 Should i be worried about the message "Thread 1 cannot allocate new log..."?
If yes: what can be the reason for it and what can I do about it?
**Update:**
When I issued a manual checkpoint using:
EXEC rdsadmin.rdsadmin_util.checkpoint;
... it did a checkpoint in less than a second and all but one log file became INACTIVE.
It seems as if it doesn't do automatic checkpoints.
Should i be worried about the message "Thread 1 cannot allocate new log..."?
If yes: what can be the reason for it and what can I do about it?
**Update:**
When I issued a manual checkpoint using:
EXEC rdsadmin.rdsadmin_util.checkpoint;
... it did a checkpoint in less than a second and all but one log file became INACTIVE.
It seems as if it doesn't do automatic checkpoints.
Reading about the first message ("cannot allocate new log") it seems as a "bad" message. The typical advice is to increase the redo log file size. So I added 4 log files, each 512 Mb. The advice was to remove the old log (128 Mb each) files but they are almost always "ACTIVE" so I have just managed to remove 1. This is the current status:
... and I still get the error message in alert.log.
The parameter archive_lag_target is set to 300 (5 minutes), so I guess that's why it switches log file every five minutes. (I don't think I can change that setting in RDS.)
Looking at the disk operations in AWS doesn't imply that the disk is under too heavy load:
Should i be worried about the message "Thread 1 cannot allocate new log..."?
If yes: what can be the reason for it and what can I do about it?
**Update:**
When I issued a manual checkpoint using:
EXEC rdsadmin.rdsadmin_util.checkpoint;
... it did a checkpoint in less than a second and all but one log file became INACTIVE.
It seems as if it doesn't do automatic checkpoints.
Asked by Björn
(133 rep)
Feb 11, 2025, 11:35 AM
Last activity: Mar 5, 2025, 09:21 PM
Last activity: Mar 5, 2025, 09:21 PM