PostgreSQL High Availability/Scalability using HAProxy and PGBouncer
22
votes
3
answers
37689
views
I have multiple PostgreSQL servers for a web application.
Typically one master and multiple slaves in hot standby mode (asynchronous streaming replication).
I use PGBouncer for connection pooling: one instance installed on each PG server (port 6432) connecting to database on localhost. I use transaction pool mode.
In order to load-balance my read-only connections on slaves, I use HAProxy (v1.5) with a conf more or less like this:
listen pgsql_pool 0.0.0.0:10001
mode tcp
option pgsql-check user ha
balance roundrobin
server master 10.0.0.1:6432 check backup
server slave1 10.0.0.2:6432 check
server slave2 10.0.0.3:6432 check
server slave3 10.0.0.4:6432 check
So, my web application connects to haproxy (port 10001), that load-balance connections on multiple pgbouncer configured on each PG slave.
Here is a representation graph of my current architecture:
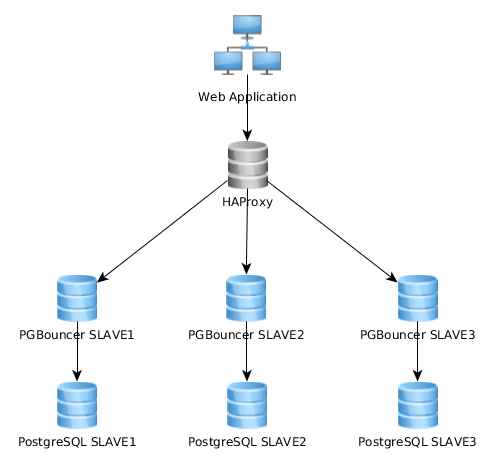 This works quite well like this, but I realize that some implements this quite differently: web application connects to a single PGBouncer instance that connects to HAproxy which load-balance over multiple PG servers:
This works quite well like this, but I realize that some implements this quite differently: web application connects to a single PGBouncer instance that connects to HAproxy which load-balance over multiple PG servers:
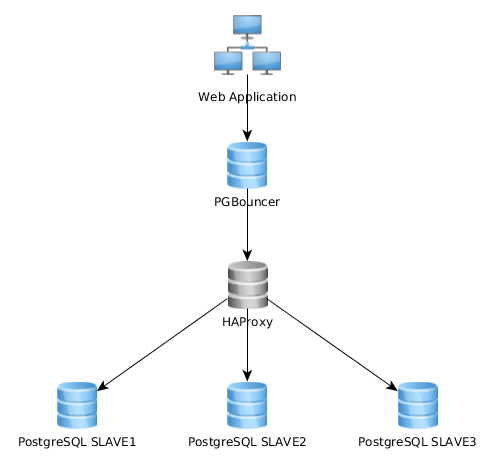 What's the best approach? The first one (my current one) or the second one? Are there any advantages of one solution over the other?
Thanks
What's the best approach? The first one (my current one) or the second one? Are there any advantages of one solution over the other?
Thanks
This works quite well like this, but I realize that some implements this quite differently: web application connects to a single PGBouncer instance that connects to HAproxy which load-balance over multiple PG servers:
What's the best approach? The first one (my current one) or the second one? Are there any advantages of one solution over the other?
Thanks
Asked by Nicolas Payart
(2508 rep)
Jan 10, 2014, 04:55 PM
Last activity: Oct 27, 2020, 11:25 AM
Last activity: Oct 27, 2020, 11:25 AM