Is there any decent speech recognition software for Linux?
125
votes
13
answers
88532
views
The short version of the question: I am looking for a speech recognition software that runs on Linux and has decent accuracy and usability. Any license and price is fine. It should not be restricted to voice commands, as I want to be able to dictate text.
----------
More details:
I have unsatisfyingly tried the following:
- [CMU Sphinx](http://cmusphinx.sourceforge.net/)
- [CVoiceControl](http://www.kiecza.net/daniel/linux/)
- [Ears](http://www.speech.cs.cmu.edu/comp.speech/Section6/Recognition/ears.html)
- [Julius](http://julius.osdn.jp/)
- [Kaldi](http://kaldi.sourceforge.net/) (e.g., [Kaldi GStreamer server](https://github.com/alumae/kaldi-gstreamer-server))
- [IBM ViaVoice](https://web.archive.org/web/19990508201353/http://biz.yahoo.com/bw/990426/ny_ibm_1.html) (used to run on Linux but was discontinued years ago)
- [NICO ANN Toolkit](http://nico.nikkostrom.com/)
- [OpenMindSpeech](http://freespeech.sourceforge.net/)
- [RWTH ASR](http://www-i6.informatik.rwth-aachen.de/rwth-asr/)
- [shout](http://shout-toolkit.sourceforge.net/)
- [silvius](http://voxhub.io/silvius) (built on the Kaldi speech recognition toolkit)
- [Simon Listens](http://simon-listens.org/index.php?id=122)
- [ViaVoice / Xvoice](http://xvoice.sourceforge.net/)
- [Wine + Dragon NaturallySpeaking](https://appdb.winehq.org/objectManager.php?sClass=application&iId=2077) + [NatLink](https://sourceforge.net/projects/natlink/) + [dragonfly](https://pypi.python.org/pypi/dragonfly) + [damselfly](https://github.com/TristenHayfield/damselfly)
- https://github.com/DragonComputer/Dragonfire : only accepts voice commands
All the above-mentioned native Linux solutions have both poor accuracy and usability (or some don't allow free-text dictation but only voice commands). By poor accuracy, I mean an accuracy significantly below the one the speech recognition software I mentioned below for other platforms have. As for Wine + Dragon NaturallySpeaking, in my experience it keeps crashing, and I don't seem to be the only one to have [such issues]((https://appdb.winehq.org/objectManager.php?sClass=application&iId=2077)) unfortunately.
On Microsoft Windows I use Dragon NaturallySpeaking, on Apple Mac OS X I use Apple Dictation and DragonDictate, on Android I use Google speech recognition, and on iOS I use the built-in Apple speech recognition.
Baidu Research released [yesterday](http://slashdot.org/story/16/01/17/1318228/baidu-releases-open-source-artificial-intelligence-code) the [code](https://github.com/baidu-research/warp-ctc) for its speech recognition library using [Connectionist Temporal Classification](http://www.cs.toronto.edu/~graves/icml_2006.pdf) implemented with Torch. Benchmarks from [Gigaom](https://gigaom.com/2014/12/18/baidu-claims-deep-learning-breakthrough-with-deep-speech/) are encouraging as shown in the table below, but I am not aware of any good wrapper around to make it usable without quite some coding (and a large training data set):
>|System |Clean (94) |Noisy (82) |Combined (176)
>|:---------------|:----------:|:----------:|:------------:
>|Apple Dictation | 14.24 | 43.76 | 26.73
>|Bing Speech | 11.73 | 36.12 | 22.05
>|Google API | 6.64 | 30.47 | 16.72
>|wit.ai | 7.94 | 35.06 | 19.41
>|**Deep Speech** | **6.56** |**19.06** |**11.85**
>
>Table 4: Results (%WER) for 3 systems evaluated on the original audio. All systems are scored _only_ on the utterances with predictions given by all systems. The number in the parentheses next to each dataset, e.g. Clean (94), is the number of utterances scored.
There exist some very alpha open-source projects:
- https://github.com/mozilla/DeepSpeech (part of Mozilla's Vaani project: http://vaani.io ([mirror](https://web.archive.org/web/20170424002550/http://vaani.io/info.html)))
- https://github.com/pannous/tensorflow-speech-recognition
- Vox, a system to control a Linux system using Dragon NaturallySpeaking: https://github.com/Franck-Dernoncourt/vox_linux + https://github.com/Franck-Dernoncourt/vox_windows
- https://github.com/facebookresearch/wav2letter
- https://github.com/espnet/espnet
- http://github.com/tensorflow/lingvo (to be released by Google, mentioned at Interspeech 2018)
I am also aware of this [attempt at tracking states of the arts and recent results (bibliography) on speech recognition.](https://github.com/syhw/wer_are_we) as well as this [benchmark of existing speech recognition APIs](https://github.com/Franck-Dernoncourt/ASR_benchmark) .
----
I am aware of [Aenea](https://github.com/dictation-toolbox/aenea) , which allows speech recognition via Dragonfly on one computer to send events to another, but it has some latency cost:
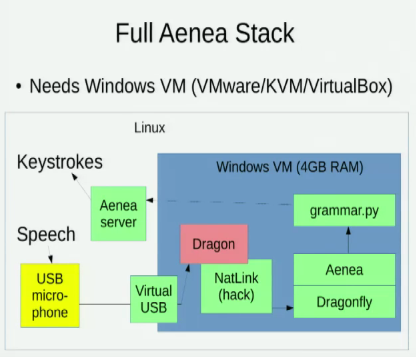 I am also aware of these two talks exploring Linux option for speech recognition:
- [2016 - The Eleventh HOPE: Coding by Voice with Open Source Speech Recognition](https://www.youtube.com/watch?v=YRyYIIFKsdU) (David Williams-King)
- [2014 - Pycon: Using Python to Code by Voice](https://www.youtube.com/watch?v=8SkdfdXWYaI) (Tavis Rudd)
I am also aware of these two talks exploring Linux option for speech recognition:
- [2016 - The Eleventh HOPE: Coding by Voice with Open Source Speech Recognition](https://www.youtube.com/watch?v=YRyYIIFKsdU) (David Williams-King)
- [2014 - Pycon: Using Python to Code by Voice](https://www.youtube.com/watch?v=8SkdfdXWYaI) (Tavis Rudd)
I am also aware of these two talks exploring Linux option for speech recognition:
- [2016 - The Eleventh HOPE: Coding by Voice with Open Source Speech Recognition](https://www.youtube.com/watch?v=YRyYIIFKsdU) (David Williams-King)
- [2014 - Pycon: Using Python to Code by Voice](https://www.youtube.com/watch?v=8SkdfdXWYaI) (Tavis Rudd)
Asked by Franck Dernoncourt
(5533 rep)
Jan 18, 2016, 06:04 PM
Last activity: Mar 19, 2025, 08:46 PM
Last activity: Mar 19, 2025, 08:46 PM