I want to generate a CHM/... e-book by wgetting with a subset condition: download a subset of data recursively in the website that is within HTML class 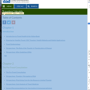 Output: just index.html
Expected output: e-book CHM and/or other format
Wget Proposals
1. TimS
wget -w5 --random-wait -r -nd -e robots=off -A".html" -U mozilla https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: same as with the first code.
2. With Rejection List
wget -w5 --random-wait -r -nd -e robots=off -A".html" \
-U mozilla -R css https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: same as without rejection lists.
3. Another variant
wget -w5 --random-wait -r -nd -e robots=off -A".html" \
-U mozilla https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: similar as before.
The tool www.html2pdf.it gives
> Cannot get http://wwwnc.cdc.gov/travel/yellowbook/2016/table-of-contents : http status code 404
OS: Debian 8.7
Output: just index.html
Expected output: e-book CHM and/or other format
Wget Proposals
1. TimS
wget -w5 --random-wait -r -nd -e robots=off -A".html" -U mozilla https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: same as with the first code.
2. With Rejection List
wget -w5 --random-wait -r -nd -e robots=off -A".html" \
-U mozilla -R css https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: same as without rejection lists.
3. Another variant
wget -w5 --random-wait -r -nd -e robots=off -A".html" \
-U mozilla https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: similar as before.
The tool www.html2pdf.it gives
> Cannot get http://wwwnc.cdc.gov/travel/yellowbook/2016/table-of-contents : http status code 404
OS: Debian 8.7
.container for a CHM book. Pseudocode
0. wget recursively all links of chapters
# TODO returns only index.html
wget --random-wait -r -p -nd -e robots=off -A".html" \
-U mozilla https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
1. Contents in the current main page in .container of Fig. 1 and contents in the daughter pages of links.
2. create CHM e-book and/or other format
Fig. 1 Inspection of CDC Yellow Book .container
Output: just index.html
Expected output: e-book CHM and/or other format
Wget Proposals
1. TimS
wget -w5 --random-wait -r -nd -e robots=off -A".html" -U mozilla https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: same as with the first code.
2. With Rejection List
wget -w5 --random-wait -r -nd -e robots=off -A".html" \
-U mozilla -R css https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: same as without rejection lists.
3. Another variant
wget -w5 --random-wait -r -nd -e robots=off -A".html" \
-U mozilla https://wwwnc.cdc.gov/travel/yellowbook/2018/table-of-contents
Output: similar as before.
The tool www.html2pdf.it gives
> Cannot get http://wwwnc.cdc.gov/travel/yellowbook/2016/table-of-contents : http status code 404
OS: Debian 8.7
Asked by Léo Léopold Hertz 준영
(7138 rep)
Apr 19, 2016, 04:01 PM
Last activity: Mar 7, 2025, 10:36 PM
Last activity: Mar 7, 2025, 10:36 PM