degraded iops and throughput on a linux machine in a cluster
1
vote
0
answers
285
views
we have a linux-based cluster on AWS with 8 workers.
OS version (taken from /proc/version) is:
Linux version 5.4.0-1029-aws (buildd@lcy01-amd64-021) (gcc version 7.5.0 (Ubuntu 7.5.0-3ubuntu1~18.04)) #30~18.04.1-Ubuntu SMP Tue Oct 20 11:09:25 UTC 2020
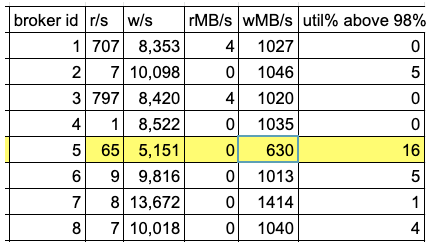
worker id 5 was added recently, and the problem that we see is that during times of high disk util% due to a burst of writes into the workers, the disk mounted to that worker's data dir (/dev/nvme1n1p1) shows a degraded performance in terms of w/sec and wMB/sec, which are much lower on that worker compared to the other 7 workers (~40% less iops and throughput on that broker).
the data in this table was taken from running iostat -x on all the brokers, starting at the same time and ending after 3 hours during peak time. the cluster handles ~2M messages/sec.
another strange behavior is that broker id 7 has ~40% more iops and throughput during bursts of writes compared to the other brokers.
worker type is i3en.3xlarge with one nvme ssd 7.5TB.
**any idea as to what can cause such degraded performance in worker id 5 (or such a good performance on broker id 7)?**
this issue is causing the consumers from this cluster to lag during high writes because worker id 5 gets into high iowait, and in case some consumer reads gets into lag and performs reads from the disk then the iowait on worker id 5 climbs into ~70% and all consumers start to lag and also the producers get OOM due buffered messages that the broker doesn't accept.
Asked by Elad Eldor
(11 rep)
May 13, 2021, 04:11 PM
Last activity: May 15, 2021, 05:02 PM
Last activity: May 15, 2021, 05:02 PM