Using tesseract for character recongniton, result is not as expected (much worse). How to get better?
1
vote
0
answers
568
views
I wanted to add output of Linux boot to my question and decided to try to use optical character recognition thinking now in 2022 surely there should be decent open source options (have not tried OCR for a long time). Links found via Web search "praise"  oon usb 1-@: |
“3792661 usb 1-8: New USB device found, idVendor=1343, idProduct:
7.983163] usb 1-8: New USB dev bs P luct=5662, bedDevice=16.6?
re eh peeled haibbetaia a
: new high-speed USB device number 5 PhS |
i
Per Samm SCR Can)
t pela ee rcpt PP cay
: 2.998668) usb 1-8: er
t
Ct
When only small part is processed:
2.837811) usb 1-8: new high-speed USB device number 5 using xhei_hed
2.979266] usb 1-8: New USB device ECU CREME Cnt ttc cain Tt teen Td
7.983163] usb 1-8: New USB device strings: Mfr=1, Product=2, SerialNumbers@
?.9869291 usb 1-8: Product: Integrated Camera
Added 1:
Tried again smaller and less skewed picture, I guess software considers time stamps as separate column, I have not seen on man page options to tweak that:
oon usb 1-@: |
“3792661 usb 1-8: New USB device found, idVendor=1343, idProduct:
7.983163] usb 1-8: New USB dev bs P luct=5662, bedDevice=16.6?
re eh peeled haibbetaia a
: new high-speed USB device number 5 PhS |
i
Per Samm SCR Can)
t pela ee rcpt PP cay
: 2.998668) usb 1-8: er
t
Ct
When only small part is processed:
2.837811) usb 1-8: new high-speed USB device number 5 using xhei_hed
2.979266] usb 1-8: New USB device ECU CREME Cnt ttc cain Tt teen Td
7.983163] usb 1-8: New USB device strings: Mfr=1, Product=2, SerialNumbers@
?.9869291 usb 1-8: Product: Integrated Camera
Added 1:
Tried again smaller and less skewed picture, I guess software considers time stamps as separate column, I have not seen on man page options to tweak that:
 f a eg
| 7.849264]
Device= 6.44
f 7 .6492961
| 7.849355]
f 7.849415]
[ 7.849492]
| Van eos
fl 7.861846]
if Va ACB
| 7.864776]
if eel Be
Ha Bs) bs 4
if be A be ge
C ie BD LB
ce B)
te] Bs]
rage
lb eae
8.962076)
ie Ke Lb
9.600567)
9.696957)
9 .6970371
YS SF SS Se
usb 1-8: new high-speed USB device number 4 using xhci_hcd
usb 1-8: New USB device found, idVendor=04f2, idProduct=b449, bed
usb 1-8: New USB device strings: Mfr=3, Product=1, SerialNumber=2
usb 1-8: Product: Integrated Camera
usb 1-8: Manufacturer: Chicony Electronics Co.,Ltd.
usb 1-8: SerialNumber: 6x0001
usb-storage 1-1:1.6: USB Mass Storage device detected
scsi host3:
usb-storage 1-1:1.6
usbcore: registered new interface driver usb-storage
usbcore: registered new interface driver uas
scsi 3:0:6:@: Direct-fAccess General UDisk eg
sd 3:0:0:0: Attached scsi generic sgi type @
eM Pee PM eA PA ed) te) ae
Py Me ee dd
Py ee ee eee dm
sd 3:0:0:0: [sdb] Assuming drive cache: write through
sdb: sdbi sdb2 sdb3
sd 3:0:0:0: [sdb] Attached SCSI removable disk
squashfs: version 4.6 (2609/01/31) Phillip Lougher
Copying live image to RAM...
Ca ewe te Mae
f a eg
| 7.849264]
Device= 6.44
f 7 .6492961
| 7.849355]
f 7.849415]
[ 7.849492]
| Van eos
fl 7.861846]
if Va ACB
| 7.864776]
if eel Be
Ha Bs) bs 4
if be A be ge
C ie BD LB
ce B)
te] Bs]
rage
lb eae
8.962076)
ie Ke Lb
9.600567)
9.696957)
9 .6970371
YS SF SS Se
usb 1-8: new high-speed USB device number 4 using xhci_hcd
usb 1-8: New USB device found, idVendor=04f2, idProduct=b449, bed
usb 1-8: New USB device strings: Mfr=3, Product=1, SerialNumber=2
usb 1-8: Product: Integrated Camera
usb 1-8: Manufacturer: Chicony Electronics Co.,Ltd.
usb 1-8: SerialNumber: 6x0001
usb-storage 1-1:1.6: USB Mass Storage device detected
scsi host3:
usb-storage 1-1:1.6
usbcore: registered new interface driver usb-storage
usbcore: registered new interface driver uas
scsi 3:0:6:@: Direct-fAccess General UDisk eg
sd 3:0:0:0: Attached scsi generic sgi type @
eM Pee PM eA PA ed) te) ae
Py Me ee dd
Py ee ee eee dm
sd 3:0:0:0: [sdb] Assuming drive cache: write through
sdb: sdbi sdb2 sdb3
sd 3:0:0:0: [sdb] Attached SCSI removable disk
squashfs: version 4.6 (2609/01/31) Phillip Lougher
Copying live image to RAM...
Ca ewe te Mae
tesseract. https://www.linuxlinks.com/ocrtools/ second best on chart. https://askubuntu.com/questions/16268/whats-the-best-simplest-ocr-solution
> Tesseract is probably the most accurate open source OCR engine
> available.
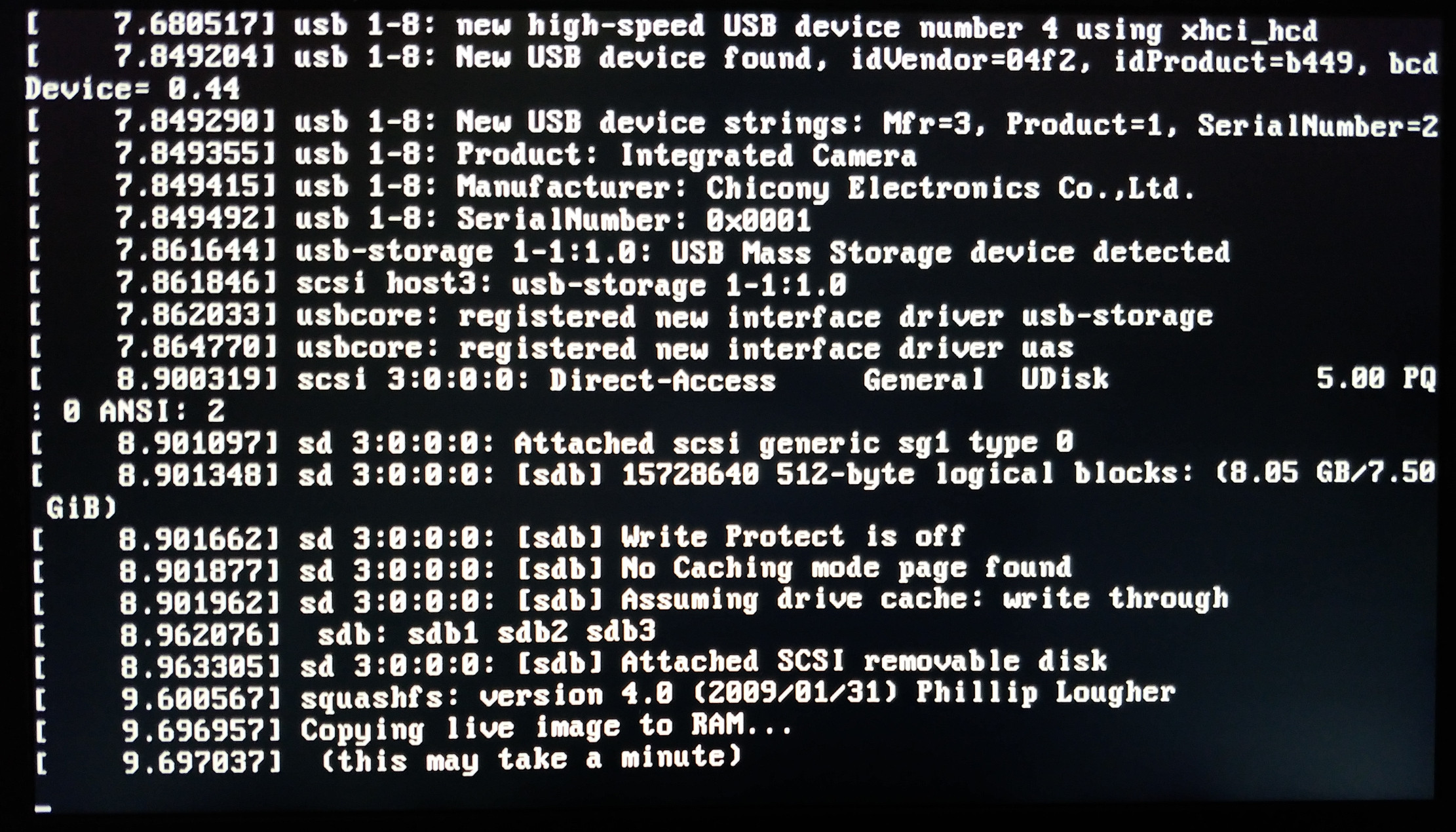
I've installed it from distro via apt-get and run. Result with out-of-the-box is IMO awful. Why? Maybe it can be ealily fixed? Or advice another package that does the job. The page I've tried to recognize lacks pictures, as I see it it is rather easy task. See below the result:
Edit: in fact result when that small part is processed were much better, but when whole is processed than results are not ok. I understand making lines more horizontal and not skewed might help a lot, still I was hoping software got good at recognizing non-perfectly aligned text.
oon usb 1-@: |
“3792661 usb 1-8: New USB device found, idVendor=1343, idProduct:
7.983163] usb 1-8: New USB dev bs P luct=5662, bedDevice=16.6?
re eh peeled haibbetaia a
: new high-speed USB device number 5 PhS |
i
Per Samm SCR Can)
t pela ee rcpt PP cay
: 2.998668) usb 1-8: er
t
Ct
When only small part is processed:
2.837811) usb 1-8: new high-speed USB device number 5 using xhei_hed
2.979266] usb 1-8: New USB device ECU CREME Cnt ttc cain Tt teen Td
7.983163] usb 1-8: New USB device strings: Mfr=1, Product=2, SerialNumbers@
?.9869291 usb 1-8: Product: Integrated Camera
Added 1:
Tried again smaller and less skewed picture, I guess software considers time stamps as separate column, I have not seen on man page options to tweak that:
f a eg
| 7.849264]
Device= 6.44
f 7 .6492961
| 7.849355]
f 7.849415]
[ 7.849492]
| Van eos
fl 7.861846]
if Va ACB
| 7.864776]
if eel Be
Ha Bs) bs 4
if be A be ge
C ie BD LB
ce B)
te] Bs]
rage
lb eae
8.962076)
ie Ke Lb
9.600567)
9.696957)
9 .6970371
YS SF SS Se
usb 1-8: new high-speed USB device number 4 using xhci_hcd
usb 1-8: New USB device found, idVendor=04f2, idProduct=b449, bed
usb 1-8: New USB device strings: Mfr=3, Product=1, SerialNumber=2
usb 1-8: Product: Integrated Camera
usb 1-8: Manufacturer: Chicony Electronics Co.,Ltd.
usb 1-8: SerialNumber: 6x0001
usb-storage 1-1:1.6: USB Mass Storage device detected
scsi host3:
usb-storage 1-1:1.6
usbcore: registered new interface driver usb-storage
usbcore: registered new interface driver uas
scsi 3:0:6:@: Direct-fAccess General UDisk eg
sd 3:0:0:0: Attached scsi generic sgi type @
eM Pee PM eA PA ed) te) ae
Py Me ee dd
Py ee ee eee dm
sd 3:0:0:0: [sdb] Assuming drive cache: write through
sdb: sdbi sdb2 sdb3
sd 3:0:0:0: [sdb] Attached SCSI removable disk
squashfs: version 4.6 (2609/01/31) Phillip Lougher
Copying live image to RAM...
Ca ewe te Mae
Asked by Martian2020
(1443 rep)
Jan 10, 2022, 06:35 AM
Last activity: Jan 10, 2022, 07:13 AM
Last activity: Jan 10, 2022, 07:13 AM