DRBD: "Couldn't mount device [/dev/drbd0] as /mydata" when failing over or rebooting node
0
votes
1
answer
4348
views
I'm creating a cluster system using two ESXi hosts, with a CentOS 7 server on each.
Going through I created the filesystem, and it mounts on 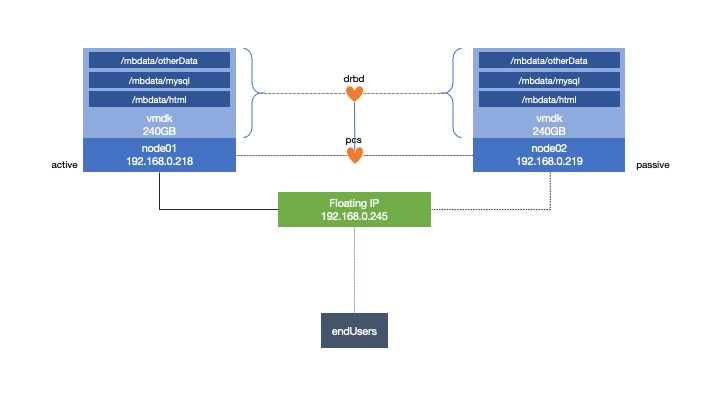 When it does run I have:
[root@node01 ~]# pcs status
Cluster name: mb_cluster
Stack: corosync
Current DC: node01 (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Fri May 8 09:46:59 2020
Last change: Fri May 8 09:22:59 2020 by hacluster via crmd on node01
2 nodes configured
8 resources configured
Online: [ node01, node02 ]
Full list of resources:
mb-fence-01 (stonith:fence_vmware_soap): Started node01
mb-fence-02 (stonith:fence_vmware_soap): Started node02
Master/Slave Set: mb-clone [mb-data]
Masters: [ node01 ]
Slaves: [ node02 ]
Resource Group: mb-group
mb-drbdFS (ocf::heartbeat:Filesystem): Started node01
mb-vip (ocf::heartbeat:IPaddr2): Started node01
mb-web (ocf::heartbeat:apache): Started node01
mb-sql (ocf::heartbeat:mysql): Started node01
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
And the constraints:
[root@node01 ~]# pcs constraint list --full
Location Constraints:
Resource: mb-fence-01
Enabled on: node01 (score:INFINITY) (id:location-mb-fence-01-node01-INFINITY)
Resource: mb-fence-02
Enabled on: node02 (score:INFINITY) (id:location-mb-fence-02-node02-INFINITY)
Ordering Constraints:
start mb-drbdFS then start mb-vip (kind:Mandatory) (id:order-mb-drbdFS-mb-vip-mandatory)
start mb-vip then start mb-web (kind:Mandatory) (id:order-mb-vip-mb-web-mandatory)
start mb-vip then start mb-sql (kind:Mandatory) (id:order-mb-vip-mb-sql-mandatory)
promote mb-clone then start mb-drbdFS (kind:Mandatory) (id:order-mb-clone-mb-drbdFS-mandatory)
Colocation Constraints:
mb-drbdFS with mb-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-mb-drbdFS-mb-clone-INFINITY)
mb-vip with mb-drbdFS (score:INFINITY) (id:colocation-mb-vip-mb-drbdFS-INFINITY)
mb-web with mb-vip (score:INFINITY) (id:colocation-mb-web-mb-vip-INFINITY)
mb-sql with mb-vip (score:INFINITY) (id:colocation-mb-sql-mb-vip-INFINITY)
Ticket Constraints:
When it does run I have:
[root@node01 ~]# pcs status
Cluster name: mb_cluster
Stack: corosync
Current DC: node01 (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Fri May 8 09:46:59 2020
Last change: Fri May 8 09:22:59 2020 by hacluster via crmd on node01
2 nodes configured
8 resources configured
Online: [ node01, node02 ]
Full list of resources:
mb-fence-01 (stonith:fence_vmware_soap): Started node01
mb-fence-02 (stonith:fence_vmware_soap): Started node02
Master/Slave Set: mb-clone [mb-data]
Masters: [ node01 ]
Slaves: [ node02 ]
Resource Group: mb-group
mb-drbdFS (ocf::heartbeat:Filesystem): Started node01
mb-vip (ocf::heartbeat:IPaddr2): Started node01
mb-web (ocf::heartbeat:apache): Started node01
mb-sql (ocf::heartbeat:mysql): Started node01
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
And the constraints:
[root@node01 ~]# pcs constraint list --full
Location Constraints:
Resource: mb-fence-01
Enabled on: node01 (score:INFINITY) (id:location-mb-fence-01-node01-INFINITY)
Resource: mb-fence-02
Enabled on: node02 (score:INFINITY) (id:location-mb-fence-02-node02-INFINITY)
Ordering Constraints:
start mb-drbdFS then start mb-vip (kind:Mandatory) (id:order-mb-drbdFS-mb-vip-mandatory)
start mb-vip then start mb-web (kind:Mandatory) (id:order-mb-vip-mb-web-mandatory)
start mb-vip then start mb-sql (kind:Mandatory) (id:order-mb-vip-mb-sql-mandatory)
promote mb-clone then start mb-drbdFS (kind:Mandatory) (id:order-mb-clone-mb-drbdFS-mandatory)
Colocation Constraints:
mb-drbdFS with mb-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-mb-drbdFS-mb-clone-INFINITY)
mb-vip with mb-drbdFS (score:INFINITY) (id:colocation-mb-vip-mb-drbdFS-INFINITY)
mb-web with mb-vip (score:INFINITY) (id:colocation-mb-web-mb-vip-INFINITY)
mb-sql with mb-vip (score:INFINITY) (id:colocation-mb-sql-mb-vip-INFINITY)
Ticket Constraints:
node1.
When I perform a standby or reboot from node01 to node02 the failover works as it should. However, if I perform it from node02 back to node01 it returns a resource error about failing to mount the filesystem under /mbdata
I am receiving this message:
Failed Resource Actions:
* mb-drbdFS_start_0 on node01 'unknown error' (1): call=75, status=complete, exitreason='Couldn't mount device [/dev/drbd0] as /mbdata',
last-rc-change='Thu May 7 16:09:25 2020', queued=1ms, exec=129ms
When I clean the resources, and node02 is online it starts running again. I have googled to see why I am getting this error, but the only thing I can see is that the server is not notifying the new master that is in fact the master (not slave). But I haven't found anything to help me to activate this.
I have tried umount on both systems - but usually get on node02 that it is not mounted. I have tried mounting the system on both (but then one is read-only and defeats the purpose of the cluster controlling it). I was following a tutorial in the beginning but they didn't list having the error - they just said it kicks over to the new node so I'm lost!
The only difference I have done is not use /mnt as the destination, but my own directory - but I didn't think that would be the problem.
What I'm trying to have is:
- have a fence on each ESXi host (physical server, to reboot it's own VM)
- have a DRBD storage so I can have shared storage
- have a virtual IP for client access
- have Apache to run the web server
- have MariaDb for the SQL database
- run them on the same servers (colocation) and have the other as full standby
When it does run I have:
[root@node01 ~]# pcs status
Cluster name: mb_cluster
Stack: corosync
Current DC: node01 (version 1.1.21-4.el7-f14e36fd43) - partition with quorum
Last updated: Fri May 8 09:46:59 2020
Last change: Fri May 8 09:22:59 2020 by hacluster via crmd on node01
2 nodes configured
8 resources configured
Online: [ node01, node02 ]
Full list of resources:
mb-fence-01 (stonith:fence_vmware_soap): Started node01
mb-fence-02 (stonith:fence_vmware_soap): Started node02
Master/Slave Set: mb-clone [mb-data]
Masters: [ node01 ]
Slaves: [ node02 ]
Resource Group: mb-group
mb-drbdFS (ocf::heartbeat:Filesystem): Started node01
mb-vip (ocf::heartbeat:IPaddr2): Started node01
mb-web (ocf::heartbeat:apache): Started node01
mb-sql (ocf::heartbeat:mysql): Started node01
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
And the constraints:
[root@node01 ~]# pcs constraint list --full
Location Constraints:
Resource: mb-fence-01
Enabled on: node01 (score:INFINITY) (id:location-mb-fence-01-node01-INFINITY)
Resource: mb-fence-02
Enabled on: node02 (score:INFINITY) (id:location-mb-fence-02-node02-INFINITY)
Ordering Constraints:
start mb-drbdFS then start mb-vip (kind:Mandatory) (id:order-mb-drbdFS-mb-vip-mandatory)
start mb-vip then start mb-web (kind:Mandatory) (id:order-mb-vip-mb-web-mandatory)
start mb-vip then start mb-sql (kind:Mandatory) (id:order-mb-vip-mb-sql-mandatory)
promote mb-clone then start mb-drbdFS (kind:Mandatory) (id:order-mb-clone-mb-drbdFS-mandatory)
Colocation Constraints:
mb-drbdFS with mb-clone (score:INFINITY) (with-rsc-role:Master) (id:colocation-mb-drbdFS-mb-clone-INFINITY)
mb-vip with mb-drbdFS (score:INFINITY) (id:colocation-mb-vip-mb-drbdFS-INFINITY)
mb-web with mb-vip (score:INFINITY) (id:colocation-mb-web-mb-vip-INFINITY)
mb-sql with mb-vip (score:INFINITY) (id:colocation-mb-sql-mb-vip-INFINITY)
Ticket Constraints:
Asked by markb
(143 rep)
May 7, 2020, 06:34 AM
Last activity: May 8, 2020, 12:16 AM
Last activity: May 8, 2020, 12:16 AM