Database Administrators
Q&A for database professionals who wish to improve their database skills
Latest Questions
0
votes
1
answers
109
views
How does the graph database (Neo4j) solve the `O(n)` problem as data grows compared to RDBMs
A training course in the Neo4j Academy mentions that: > When querying across tables, the joins are computed at read-time, > using an index to find the corresponding rows in the target table. The > more data added to the database, the larger the index grows, the > slower the response time. > > This p...
A training course in the Neo4j Academy mentions that:
> When querying across tables, the joins are computed at read-time,
> using an index to find the corresponding rows in the target table. The
> more data added to the database, the larger the index grows, the
> slower the response time.
>
> This problem is known as the “Big O” or O(n) notation.
This sounds quite vague to me because when the data grows up, even for the graph database this also means that more relationships are added to the graph, and so the query response time will also be slower?
Kt Student
(115 rep)
Mar 7, 2025, 04:55 AM
• Last activity: Mar 7, 2025, 06:29 PM
0
votes
1
answers
32
views
Why `MATCH (p:Person)-[:ACTED_IN]->(m) WHERE 'Neo' IN r.roles RETURN p.name` returns 3 rows for only 1 node?
In Neo4j, when I use the following query: MATCH (p:Person)-[:ACTED_IN]->(m) WHERE 'Neo' IN r.roles RETURN p then it returns only one Person node. But when I change the query to: MATCH (p:Person)-[:ACTED_IN]->(m) WHERE 'Neo' IN r.roles RETURN p.name then it returns 3 rows. [![Neo4j query results][1]]...
In Neo4j, when I use the following query:
MATCH (p:Person)-[:ACTED_IN]->(m) WHERE 'Neo' IN r.roles RETURN p
then it returns only one Person node.
But when I change the query to:
MATCH (p:Person)-[:ACTED_IN]->(m) WHERE 'Neo' IN r.roles RETURN p.name
then it returns 3 rows.
 This is strange to me since I expect there should be only one row returned?
This is strange to me since I expect there should be only one row returned?
This is strange to me since I expect there should be only one row returned?
Kt Student
(115 rep)
Feb 7, 2025, 03:18 AM
• Last activity: Feb 7, 2025, 05:43 PM
1
votes
1
answers
82
views
MongoDB - Finding the degree of separation of two users
As suggested in [this][1] post, I'm proposing here my question. I have a MongoDB collections *spots* which has documents representing the friendship between two users { "_id": "64a337de4538a04610900f0c", "user1": "6468022102781d442b82afd7", "user2": "648c7b6b75231cd99e43d7ab", "areFriends": true } M...
As suggested in this post, I'm proposing here my question.
I have a MongoDB collections *spots* which has documents representing the friendship between two users
{
"_id": "64a337de4538a04610900f0c",
"user1": "6468022102781d442b82afd7",
"user2": "648c7b6b75231cd99e43d7ab",
"areFriends": true
}
My goal is to write an aggregation which, given two user's IDs, returns the degree of separation of them.
To be clear, something like that:
- 1 = direct friends
- 2 = friends of friends
- 3+ ecc..
I came across the above example of $graphLookup, and now I am wondering how to implement something similar.
The difference between my case and the other post is that my documents have not a unidirectional relation (from-to) but a bidirectional (user1, user2); so, there is not guarantee about that the wanted user is stored as user1 or user2.
In other sections of my code, I solve this problem ordering the input ids or using conditions like this:
$cond: {
if: { $eq: ['$user1', userId] },
then: '$user2',
else: '$user1',
},
However, I've understood that conditions are not supported as filed (like *connectFromField*) in *$graphLookup*
Is anyone have a clue on how to face this particular problem, it would be very appreciated. Thanks.
**EDIT**
this is a revised version of the aggregation pipeline proposed by Ray
{ $match: { user1: id1 } },
{
$graphLookup: {
from: 'spots',
startWith: '$user1',
connectFromField: 'user2',
connectToField: 'user1',
as: 'friendshipsViewLookup',
depthField: 'degree',
maxDepth: 2,
},
},
{
$unwind: {
path: '$friendshipsViewLookup',
preserveNullAndEmptyArrays: true,
},
},
{ $match: { 'friendshipsViewLookup.user2': id2 } },
{
$project: {
user1: 1,
user2: '$friendshipsViewLookup.user2',
degree: {
$add: ['$friendshipsViewLookup.degree', 1],
},
},
},
{
$group: {
_id: { user1: '$user1', user2: '$user2' },
minDegree: { $min: '$degree' },
},
},
{
$project: {
user1: '$_id.user1',
user2: '$_id.user2',
degree: '$minDegree',
},
}
Niccolò Caselli
(113 rep)
Oct 12, 2024, 12:16 PM
• Last activity: Oct 14, 2024, 12:49 PM
7
votes
1
answers
394
views
Do any of the graph based/aware databases have good mechanisms for maintaining referential integrity?
Do any of the graph-based/graph-aware databases (Neo4j, ArangoDB, OrientDB, or other) have mechanisms for maintaining referential integrity on a par with those offered by relational databases? I'm exploring various document-based databases to find a suitable engine to use for adding an auxiliary dat...
Do any of the graph-based/graph-aware databases (Neo4j, ArangoDB, OrientDB, or other) have mechanisms for maintaining referential integrity on a par with those offered by relational databases?
I'm exploring various document-based databases to find a suitable engine to use for adding an auxiliary data storage to a certain project.
I discovered graph-based/multimodel databases and they seemed like a good idea, but I was surprised to find that they don't seem to offer the same level of protection of relations/links/edges that modern relational databases have.
In particular, I'm talking about linking deletions of entities/vertices with deletion of links/edges. In a relational database, I can have a foreign key constraint that links records from one table with records in another table, and will either
1. prevent deletion of record in table A if it's referenced by record in table B ("on delete no action"), or
2. delete the referencing record(s) in table B if a referenced record in table A is being deleted.
I expected to find a similar mechanics in graph-aware databases. For example, if a "comment" vertex links to a "post" vertex (forming a many-to-1 relation), then there are the following problems/challenges to solve:
1. Prevent deletion of a post while there are edges from comments to this post. This way, a comment could never have a dangling link/edge to a post. The solution would be: depending on the link/edge properties, either
1. prevent deletion of a post until all edges from comments to this post are deleted, or
2. delete all comments linking to this post when the post is being deleted.
2. Prevent deletion of an edge from a comment to a post without deleting the comment itself, to prevent the comment from not having a link/edge to a post at all.
3. Only allow creation of a comment if an edge is created to link this comment to a post at the same time.
Are mechanisms like this really lacking in graph-based databases, or was I just unable to find them?
I know that OrientDB has the "link" data type that probably solves the second and the third problem (if a link-typed property is declared mandatory and non-null, then it's impossible to create a record without specifying the link destination, and later it's impossible to break the link by un-setting the property).
However, as far as I remember, it's possible to delete the record which a link-typed property points to, thus producing a dangling link (so the first problem is not solved).
I also know that in certain databases I can use nested documents as an alternative to having multiple linked documents. However, this approach doesn't scale well (for cases when the number of linking records grows can grow indefinitely). Also, it is quite limited (it can't be used as an alternative when several links are needed, say, to a post and to a user; there are other important limitations, too).
pvgoran
(171 rep)
Apr 10, 2020, 05:56 AM
• Last activity: Jul 30, 2024, 08:06 PM
8
votes
2
answers
869
views
How can I efficiently traverse graph data with this pattern?
I have some relations embodying a directed acyclic graph that includes patterns similar to the following: [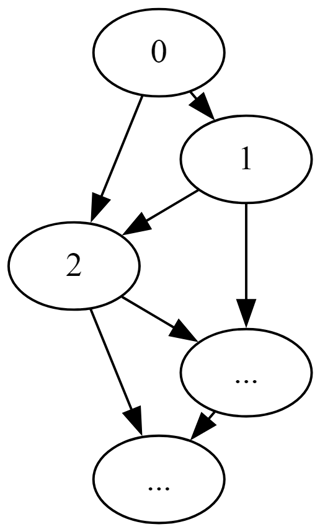](https://i.sstatic.net/R6nZl.png) I'm looking for an efficient way to traverse this graph data. Here is an example of the seemi...
I have some relations embodying a directed acyclic graph that includes patterns similar to the following:
[](https://i.sstatic.net/R6nZl.png)
I'm looking for an efficient way to traverse this graph data. Here is an example of the seemingly simple task of counting descendants of node 0:
[dbfiddle](https://dbfiddle.uk/oUdCF8WD)
DROP TABLE IF EXISTS #edges;
CREATE TABLE #edges(tail int, head int);
INSERT INTO #edges(tail,head) VALUES
(0,1), (5, 6), (10,11), (15,16),
(0,2), (5, 7), (10,12), (15,17),
(1,2), (6, 7), (11,12), (16,17),
(1,3), (7, 8), (11,13), (17,18),
(2,3), (7, 9), (12,13), (17,19),
(2,4), (8, 9), (12,14), (18,19),
(3,4), (8,10), (13,14),
(3,5), (9,10), (13,15),
(4,5), (9,11), (14,15),
(4,6), (14,16);
WITH descendents(node)
AS(
SELECT 0 as node
UNION ALL
SELECT head as node FROM descendents as prior
JOIN #edges ON prior.node = tail
)
SELECT
(SELECT COUNT(node) FROM descendents) as total_nodes,
(SELECT COUNT(node) FROM
(SELECT DISTINCT node FROM descendents) as d) as distinct_nodes
This results in the following:
total_nodes | distinct_nodes
10512 | 20
### Every path is visited instead of each node once
total_nodes seems to grow at about 2^n where n is the number of nodes in the example. This is because _every possible path_ is traversed rather than _each node once_. [This n=29 example](https://dbfiddle.uk/QScNoOxS) results in 1,305,729 total_nodes and took 75 seconds to complete on my local instance of SQL Server Express.
The obvious strategy is to only visit previously unvisited nodes on each iteration.
### Excluding redundant additions using WHERE...NOT IN does not seem to be supported
The most direct method of preventing visits to previously visited nodes would seem to be to filter right in the recursive member of the CTE as follows:
SELECT head as node FROM descendents as prior
JOIN #edges ON prior.node = tail
WHERE head NOT IN (SELECT node from descendents)
This produces the error _"Recursive member of a common table expression 'descendents' has multiple recursive references."_ I suspect this is an example of this restriction from [the documenation](https://learn.microsoft.com/en-us/sql/t-sql/queries/with-common-table-expression-transact-sql?view=sql-server-ver16) :
>The FROM clause of a recursive member must refer only one time to the CTE expression_name.
### No success avoiding previously visited nodes in the CTE's recursive member
I've tried a few different techniques for avoiding previously visited nodes as recursion progresses in the CTE. I haven't found a technique that works with this graph pattern, however. The limitation seems to boil down to the following statement from [the documentation](https://learn.microsoft.com/en-us/sql/t-sql/queries/with-common-table-expression-transact-sql?view=sql-server-ver16) :
>...aggregate functions in the recursive part of the CTE are applied to the set for the current recursion level and not to the set for the CTE. Functions like ROW_NUMBER operate only on the subset of data passed to them by the current recursion level and not the entire set of data passed to the recursive part of the CTE.
Previously visited nodes appear at different recursion levels. The above limitation seems to rule out the deduplication across recursion levels that would be needed to make this query efficient.
### Query Analysis
The following is from a run of [a query run on 42 nodes](https://dbfiddle.uk/Rp2I1iBh) invoked on my local instance of SQL Server Express. (Note that half the nodes are commented out in the fiddle because running with all 42 nodes causes the fiddle to timeout.)
The query was run as follows:
set statistics xml on;
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
WITH descendents(node)
AS(
SELECT 0 as node
UNION ALL
SELECT head as node FROM descendents as prior
JOIN #edges ON prior.node = tail
)
SELECT DISTINCT
node
FROM descendents
SET STATISTICS TIME OFF;
SET STATISTICS IO OFF;
set statistics xml off;
This resulted in the following messages:
>Started executing query at Line 1
>(76 rows affected)
>
>SQL Server parse and compile time:
>CPU time = 0 ms, elapsed time = 14 ms.
>(42 rows affected)
>
>Table 'Worktable'. Scan count 2, logical reads 943777243, physical reads 0, read-ahead reads 12117, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
>
>Table '#edges______________________________________________________________________________________________________________000000002516'. Scan count 1, logical reads 157296207, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
>
>(1 row affected)
>
>SQL Server Execution Times:
>CPU time = 2972344 ms, elapsed time = 3319271 ms.
>Total execution time: 00:55:19.424
Here is [the execution plan](https://www.brentozar.com/pastetheplan/?id=H1quxTISh) :
[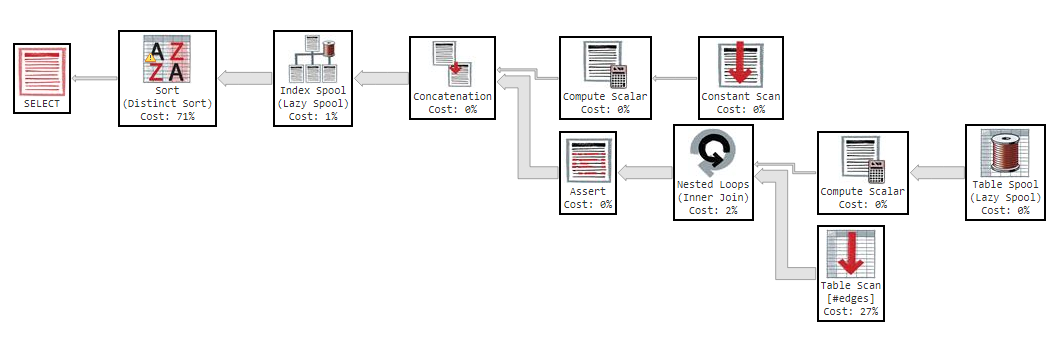](https://www.brentozar.com/pastetheplan/?id=H1quxTISh)
And these are screenshots of the tooltips for what would seem to be the most time consuming steps:
[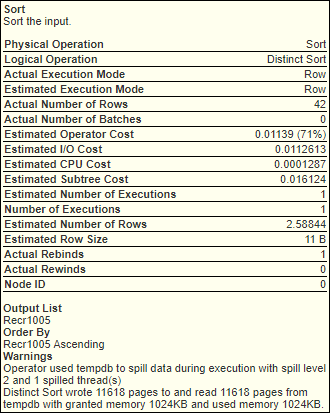](https://www.brentozar.com/pastetheplan/?id=H1quxTISh) [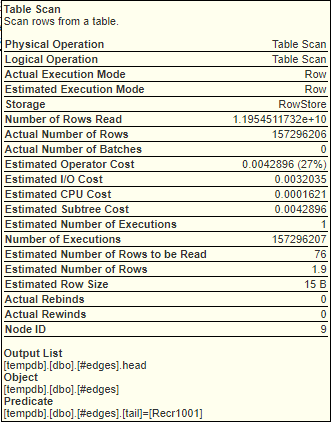](https://www.brentozar.com/pastetheplan/?id=H1quxTISh)
### Possible alternatives
I can think of a few programmatic approaches that achieve node traversal without relying on CTE recursion. I'm reluctant to prematurely abandon CTEs given the abundance of advice to prefer set logic where possible. I expect that there are some built-in SQL Server features that would support some improved approaches. The other approaches I've contemplated are as follows:
- stored procedure that implements recursion programmatically
- [hierarchyid](https://learn.microsoft.com/en-us/sql/relational-databases/hierarchical-data-sql-server?view=sql-server-ver16)
- [SQL Graph](https://learn.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-overview?view=sql-server-ver16)
I have limited or no experience with each of these approaches and so am interested in advice about the tradeoffs of these approaches for the above example.
#### Questions
1. Is there a more efficient way to traverse the graph in the above example using recursive CTEs?
2. Of the above alternatives, what are the tradeoffs?
3. Are there any other alternatives I should consider?
alx9r
(449 rep)
May 19, 2023, 05:05 PM
• Last activity: May 22, 2023, 01:26 AM
0
votes
2
answers
119
views
What is the reason for the graph dbms being better at friend-of-a-friend queries than relational dbms?
I often read that graph dbms are well suited for social networks. So for example, followers on instagram or linkedin. I read that the SQL dbms performance can degrade if the query involves multiple joins, especially if the tables being joined are large. What is the exact reason that SQL databases mi...
I often read that graph dbms are well suited for social networks. So for example, followers on instagram or linkedin. I read that the SQL dbms performance can degrade if the query involves multiple joins, especially if the tables being joined are large.
What is the exact reason that SQL databases might perform poorly under joins? Assume that the
followers table is indexed on both foreign keys.
The query:
SELECT DISTINCT f2.followed_id
FROM followers f1
JOIN followers f2 ON f1.followed_id = f2.follower_id
WHERE f1.follower_id = 4;HashAggregate (cost=253.84..257.23 rows=339 width=8)
Group Key: f2.followed_id
-> Nested Loop (cost=0.84..253.00 rows=339 width=8)
-> Index Only Scan using followers_pkey on followers f1 (cost=0.42..16.22 rows=19 width=8)
Index Cond: (follower_id = 4)
-> Index Only Scan using followers_pkey on followers f2 (cost=0.42..12.27 rows=19 width=16)
Index Cond: (follower_id = f1.followed_id)
Damiano
(23 rep)
May 6, 2023, 08:06 AM
• Last activity: May 7, 2023, 11:50 PM
2
votes
0
answers
183
views
DB design for tree structure of user access permissions
I am trying to come up with a good database design for the following problem: We have an application where users can create objects (such as notes) and link those objects to other objects, projects or users. Projects consist of assigned objects and a set of users who can access the project. How shou...
I am trying to come up with a good database design for the following problem:
We have an application where users can create objects (such as notes) and link those objects to other objects, projects or users. Projects consist of assigned objects and a set of users who can access the project.
How should we model the database to efficiently query for all objects that a user has access to, as well as for all users that have access to a given object? Access to an object is granted if one or more of the following conditions is met :
1. The user is the creator of the object
2. The object has been linked (shared) with the user
3. The user is a member of a project that the object is assigned to
4. The object is directly or indirectly linked to another object that the user has access to according to rules 1-3.
I consider using a graph database, since the amount of SQL queries when using a relational database would not be feasible. We would need recursive SQL queries.
Expected data dimensions are: 100-500 users, 100 projects and 100000-999999 objects
hg.m
(21 rep)
Mar 10, 2023, 11:25 AM
0
votes
1
answers
103
views
How to evaluate Database benchmarks ? What to consider given a specific example?
I'm trying to figure out which database to use for a project which is supposed to implement a temporal property graph model and I am looking into some benchmarks for that. I found some papers which provided some insights and results and I also found this benchmark from TigerGraph: https://www.tigerg...
I'm trying to figure out which database to use for a project which is supposed to implement a temporal property graph model and I am looking into some benchmarks for that. I found some papers which provided some insights and results and I also found this benchmark from TigerGraph:
https://www.tigergraph.com.cn/wp-content/uploads/2021/07/EN0302-GraphDatabase-Comparision-Benchmark-Report.pdf
Does anyone have any idea why ArangoDB is performing so poorly here ? Especially in comparison to Neo4j ?
Furthermore, any preferences regarding a NoSQL database which consistently needs to write data while answering mostly queries which result in large subtrees ?
EDIT: Also - if someone has links to other benchmarks i'd welcome that.
L.Rex
(101 rep)
Nov 14, 2022, 06:43 PM
• Last activity: Nov 30, 2022, 09:42 PM
0
votes
1
answers
422
views
Shortest paths on huge graphs: Neo4J or OrientDB?
Kia Ora, I have a program that very frequently requires finding the fastest path (both the node sequence and total cost/length) on graphs containing ~50k nodes. Per run, I require on the order of millions of shortest path requests. I have just finished an OrientDB implementation which has significan...
Kia Ora,
I have a program that very frequently requires finding the fastest path (both the node sequence and total cost/length) on graphs containing ~50k nodes. Per run, I require on the order of millions of shortest path requests. I have just finished an OrientDB implementation which has significantly improved the compute time over my initial, non-graphDB attempt (which simply crashed). To perform testing, I am running the server locally on a series of distributed machines.
However, in theory, would Neo4J, or another such platform, be faster again? What gains could I expect to receive? Could I host this process online, for example?
Ngā mihi.
Jordan MacLachlan
(3 rep)
Dec 10, 2021, 04:18 AM
• Last activity: Aug 23, 2022, 06:00 PM
0
votes
2
answers
4627
views
Proper way to store lots of links?
I'm doing a small crawl over multiple sites and I have a lot of links which are represented by ID's (`example.com/foo` = `354`). I'm currently storing the `link -> link` references and the link text. So in the following table page "2845" contains a link to 4479 with the text "About Us". Nothing big,...
I'm doing a small crawl over multiple sites and I have a lot of links which are represented by ID's (
example.com/foo = 354).
I'm currently storing the link -> link references and the link text. So in the following table page "2845" contains a link to 4479 with the text "About Us". Nothing big, just 3NF.
+----------+----------+-----------------+
| url_1_id | url_2_id | text |
+----------+----------+-----------------+
| 2845 | 4479 | About Us |
| 2845 | 4480 | Who We Are |
| 2845 | 4481 | What We Do |
| 2845 | 4482 | Core Principles |
| 2845 | 4483 | Research Staff |
+----------+----------+-----------------+
However, by my calculations (most of the pages containing 500-1000 links each) I should have 6GB of link data by the time I've only parsed 200k pages.
Is there a better way to store link data? Especially if there is a good way to normalize repeated navigation menus for all site pages.
Xeoncross
(109 rep)
Jan 5, 2017, 08:47 PM
• Last activity: Oct 18, 2021, 08:35 AM
12
votes
1
answers
862
views
SQL Server 2019: Memory performance with graph queries (possible memory leak)
I'm currently working on implementing an upgrade to SQL Server 2019 in order to make use of the graph features that are available in it. Our database stores records of files and their children, and the graph features allow us to quickly find all of a file's relations in either direction. Our current...
I'm currently working on implementing an upgrade to SQL Server 2019 in order to make use of the graph features that are available in it. Our database stores records of files and their children, and the graph features allow us to quickly find all of a file's relations in either direction. Our current dev environment is using SQL Server 2019 Standard (15.0.4023.6) on a Linux server.
I'm noticing a concerning problem when I run my graph queries. The server's 'internal' resource pool appears to not free up all resources after a graph query. Left unchecked, this fills up the resource pool. Larger queries will fail until the SQL Server process to be restarted. Depending on server load, this could happen in as little as 1-2 hours. This can also fill up the tempdb and threaten to fill the storage drive. The files for the tempdb also cannot be shrunk/truncated significantly until the server is restarted. In configuration, 'memory.memorylimitmb' is not set, so this problem happens when the resource pool starts to have used the better part of the default 80% of system memory (12.8 GB, with 16GB of system memory)
To set up the tables within a demo database:
CREATE TABLE FileNode (ID BIGINT NOT NULL CONSTRAINT PK_FileNode PRIMARY KEY) AS NODE
GO
CREATE TABLE FileNodeArchiveEdge AS EDGE
GO
CREATE INDEX [IX_FileNodeArchiveEdge_ChildFile] ON [dbo].[FileNodeArchiveEdge] ($from_id)
GO
CREATE INDEX [IX_FileNodeArchiveEdge_ParentFile] ON [dbo].[FileNodeArchiveEdge] ($to_id)
GOINSERT INTO [FileNode] (ID) VALUES
(1),(2),(3),(4),(5),
(6),(7),(8),(9),(10),
(11),(12),(13),(14),(15)
-- Convenient intermediate table
DECLARE @bridge TABLE (f BIGINT, t BIGINT)
INSERT INTO @bridge (f, t) VALUES
(1,4),
(4,9),
(4,10),
(1,5),
(5,11),
(11,12),
(2,5),
(2,6),
(6,13),
(6,14),
(13,15),
(14,15),
(15,12),
(7,14),
(3,7),
(3,8)
INSERT INTO FileNodeArchiveEdge
($from_id, $to_id)
SELECT
(SELECT $node_id FROM FileNode WHERE ID = f),
(SELECT $node_id FROM FileNode WHERE ID = t)
FROM @bridgeDECLARE @parentId BIGINT = 1
SELECT
LAST_VALUE(f2.ID) WITHIN GROUP (GRAPH PATH)
FROM
FileNode f1,
FileNodeArchiveEdge FOR PATH contains_file,
FileNode FOR PATH f2
WHERE
f1.ID = @parentId
AND MATCH(SHORTEST_PATH(f1(-(contains_file)->f2)+))-- Memory clerk usage
SELECT TOP(10) mc.[type] AS [Memory Clerk Type],
CAST((SUM(mc.pages_kb)/1024.0) AS DECIMAL (15,2)) AS [Memory Usage (MB)]
FROM sys.dm_os_memory_clerks AS mc WITH (NOLOCK)
GROUP BY mc.[type]
ORDER BY SUM(mc.pages_kb) DESC OPTION (RECOMPILE);
/*
Example output of above query:
Memory Clerk Type Memory Usage (MB)
------------------------------------------------------------ -----------------
USERSTORE_SCHEMAMGR 9224.26
MEMORYCLERK_SQLSTORENG 1114.73
MEMORYCLERK_SQLBUFFERPOOL 471.50
CACHESTORE_SEHOBTCOLUMNATTRIBUTE 376.47
MEMORYCLERK_SOSNODE 292.02
MEMORYCLERK_SQLGENERAL 19.84
MEMORYCLERK_SQLCLR 12.04
MEMORYCLERK_SQLQUERYPLAN 2.99
MEMORYCLERK_SQLLOGPOOL 2.61
MEMORYCLERK_SQLTRACE 2.14
*/
SELECT cache_memory_kb/1024.0 AS [cache_memory_MB],compile_memory_kb/1024 AS compile_memory_MB, used_memory_kb/1024.0 AS [used_memory_MB] FROM sys.dm_resource_governor_resource_poolsl=1000 # Number of loops
# The loop will probably need to be run 2M times or so to start to see significant usage.
c=0 # Loop tracker
touch marker # Alternate emergency stop: Remove the marker file from another terminal session.
time while [ $c -lt $l ] && [ -f "marker" ]; do
c="$((${c}+1))"
echo ${c}/${l}
# Notes: SQLCMDPASSWORD has been set in environment variable
# child-query.sql contains the above child query to loop for the children of file ID 1.
time sqlcmd -U db_user -S localhost -d DemoDatabase -i child-query.sql > /dev/null || break
done
rm marker
Alan Deutscher
(121 rep)
Mar 18, 2020, 06:32 PM
• Last activity: Aug 5, 2021, 03:22 AM
0
votes
0
answers
112
views
How to turn a complicated graph into Json Graph Format?
So having such normalized Postgres 13/14 graph of item joins: CREATE TABLE items ( item_id serial PRIMARY KEY, title text ); CREATE TABLE joins ( id serial PRIMARY KEY, item_id int, child_id int ); INSERT INTO items (item_id,title) VALUES (1,'PARENT'), (2,'LEVEL 2'), (3,'LEVEL 3.1'), (4,'LEVEL 4.1')...
So having such normalized Postgres 13/14 graph of item joins:
CREATE TABLE items (
item_id serial PRIMARY KEY,
title text
);
CREATE TABLE joins (
id serial PRIMARY KEY,
item_id int,
child_id int
);
INSERT INTO items (item_id,title) VALUES
(1,'PARENT'),
(2,'LEVEL 2'),
(3,'LEVEL 3.1'),
(4,'LEVEL 4.1'),
(5,'LEVEL 4.2'),
(6,'LEVEL 3.2');
INSERT INTO joins (item_id, child_id) VALUES
(1,2),
(2,3),
(3,2),
(3,5),
(2,6);
How to turn it into a JSON Graph Format document containing item columns as fields?
Blender
(75 rep)
Jul 23, 2021, 10:59 AM
• Last activity: Jul 25, 2021, 10:16 PM
9
votes
1
answers
717
views
Find friends of friends (recursively) efficiently using Postgresql
Objective: Users submit their Contact Books, and then the application looks for connections between users, according to their Phone Number. Something like "6 Handshakes" idea (https://en.wikipedia.org/wiki/Six_degrees_of_separation). Problem: Make this query performance close to real time. When the...
Objective: Users submit their Contact Books, and then the application looks for connections between users, according to their Phone Number. Something like "6 Handshakes" idea (https://en.wikipedia.org/wiki/Six_degrees_of_separation) .
Problem: Make this query performance close to real time. When the User submits his phone number and gets the **full** list of other phones, he may know. Plain list - without connections (graph vertices etc), but full, not paginated (this requirement is here because original goal is more complex).
Question: is it possible to achieve close-to-realtime performance with pure relational database, without Graph databases (Neo4j, etc), graph extensions (bitnine agensgraph) or workflow redesign? Any denormalization is possible, but to my understanding, it won't help.
Given:
test=# select * from connections;
user_phone | friend_phone
------------+--------------
1 | 2
1 | 3
1 | 4
2 | 6
2 | 7
2 | 8
8 | 10
8 | 11
8 | 12
20 | 30
40 | 50
60 | 70friend_phone
--------------
2
3
4
6
7
8
10
11
12
(9 rows)CREATE TABLE connections (
user_phone bigint NOT NULL,
friend_phone bigint NOT NULL
);INSERT INTO connections(user_phone, friend_phone) (
SELECT generate_series AS user_phone, generate_series(1, (random()*5000)::int) AS friend_phone from generate_series(1, 500) ORDER BY user_phone
);test=# \d connections
Table "public.connections"
Column | Type | Collation | Nullable | Default
--------------+--------+-----------+----------+---------
user_phone | bigint | | not null |
friend_phone | bigint | | not null |
Indexes:
"connections_user_phone_friend_phone_idx" UNIQUE, btree (user_phone, friend_phone)
"connections_friend_phone_idx" btree (friend_phone)
"connections_friend_phone_user_phone_idx" btree (friend_phone, user_phone)
"connections_user_phone_idx" btree (user_phone)friend_phones.count >>> user_phones.count, so index connections(friend_phones, user_phones) seems to be the most appropriate, but I've created all 4 indexes during testing.
2270852 connections records were generated. Then I run this query:
WITH RECURSIVE p AS (
SELECT friend_phone FROM connections WHERE connections.user_phone = 1
UNION
SELECT friends.friend_phone FROM connections AS friends JOIN p ON friends.user_phone = p.friend_phone
)
SELECT COUNT(friend_phone) FROM p;EXPLAIN ANALYZE looks like the following:
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=3111105.00..3111105.01 rows=1 width=8) (actual time=3151.781..3151.781 rows=1 loops=1)
CTE p
-> Recursive Union (cost=0.43..2146207.20 rows=42884347 width=8) (actual time=0.060..3148.294 rows=5002 loops=1)
-> Index Scan using connections_user_phone_idx on connections (cost=0.43..3003.69 rows=4617 width=8) (actual time=0.055..2.024 rows=4137 loops=1)
Index Cond: (user_phone = 1)
-> Merge Join (cost=4500.77..128551.66 rows=4287973 width=8) (actual time=768.577..1359.598 rows=635428 loops=2)
Merge Cond: (friends.user_phone = p_1.friend_phone)
-> Index Scan using connections_user_phone_idx on connections friends (cost=0.43..54054.59 rows=2270852 width=16) (actual time=0.013..793.467 rows=1722262 loops=2)
-> Sort (cost=4500.34..4615.77 rows=46170 width=8) (actual time=0.765..74.850 rows=637677 loops=2)
Sort Key: p_1.friend_phone
Sort Method: quicksort Memory: 65kB
-> WorkTable Scan on p p_1 (cost=0.00..923.40 rows=46170 width=8) (actual time=0.001..0.314 rows=2501 loops=2)
-> CTE Scan on p (cost=0.00..857686.94 rows=42884347 width=8) (actual time=0.062..3150.755 rows=5002 loops=1)
Planning Time: 0.409 ms
Execution Time: 3152.412 ms
(15 rows)# DB Version: 12
# OS Type: mac
# DB Type: web
# Total Memory (RAM): 16 GB
# CPUs num: 8
# Data Storage: ssd
max_connections = 200
shared_buffers = 4GB
effective_cache_size = 12GB
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.7
wal_buffers = 16MB
default_statistics_target = 100
random_page_cost = 1.1
work_mem = 5242kB
min_wal_size = 1GB
max_wal_size = 4GB
max_worker_processes = 8
max_parallel_workers_per_gather = 4
max_parallel_workers = 8
max_parallel_maintenance_workers = 4
Viktor Vsk
(213 rep)
Jul 15, 2020, 04:17 PM
• Last activity: May 23, 2021, 11:01 PM
1
votes
0
answers
29
views
What is the appropriate SQL statement/s to produce a stacked bar chart for multiple random variable distributions?
## The Objective Graph the difference between the probability distributions of sets of random variables that come from a number of different sources using a stacked bar chart (or another type of graph suited for such visualization). ## The Problem I'm not sure of the right combination of SQL SELECT...
## The Objective
Graph the difference between the probability distributions of sets of random variables that come from a number of different sources using a stacked bar chart (or another type of graph suited for such visualization).
## The Problem
I'm not sure of the right combination of SQL SELECT statement(s)/condition(s) to present the data to the graphing tool in the right way to achieve the objective above.
## The Method
### Summary
Feed the source data stored in Google Cloud Platform (GCP)'s BigQuery into Google Data Studio and use a stacked bar graph to visualize the numerous probability distributions.
### The Source Data
I'm dealing with simple binary outcomes, either a heads or tails. One trial (== one second) per source yields between 0 to 200 how many heads (1s) were counted.
The schema of the data we have stored in BigQuery is as follows:
time | source1 | source 2 | ... sourceN
---------------------------------------------
09:00:00 | 99 | 110 | 95 |
09:00:01 | 101 | 115 | 107 |
09:00:02 | 99 | 91 | 97 |
### For a Single Source
The following works fine if I'm trying to graph the results from just a single source. And as the law of probability would say, the graphed distribution is moreorless in fit with the expected bell curve.
SELECT
source1 AS src1,
COUNT(source1) AS count
FROM
rnddata
WHERE
recorded_at >= "2021-03-11 08:45:00"
AND
recorded_at < "2021-03-11 09:45:00"
GROUP BY src1
ORDER BY src1src1 | count
75 | 1
77 | 2
80 | 2
81 | 5
82 | 6
83 | 20
84 | 10
85 | 14
86 | 31
87 | 33
88 | 48
89 | 74
90 | 74
91 | 89
92 | 107
93 | 133
94 | 135
95 | 168
96 | 160
97 | 192
98 | 190
99 | 195
100 | 189
101 | 197
102 | 191
103 | 188
104 | 180
105 | 201
106 | 130
107 | 128
108 | 107
109 | 96
110 | 64
111 | 65
112 | 45
113 | 40
114 | 19
115 | 22
116 | 18
117 | 9
118 | 8
119 | 6
120 | 3
121 | 4
125 | 1src1 | src2 | count
75 | null | 1
77 | 77 | 2
80 | 00 | 2
null | 80 | 5
82 | 82 | 6
83 | null | 20
83 | 11 | null
84 | 84 | 10
pilcrowpipe
(111 rep)
May 3, 2021, 09:28 AM
3
votes
1
answers
5646
views
Recursively find the path to all leaves descending from a given parent in a tree
I'm trying to write a query to identify the path to each furthest descendant of a particular parent node in a table of tree structures like: ``` 0 1 | | 2 3 | | 4 5 / \ | *6* 8 *7* | *9* ``` There are many parents, all children have one parent, parents have 0-5 children (but the graph is very "long"...
I'm trying to write a query to identify the path to each furthest descendant of a particular parent node in a table of tree structures like:
0 1
| |
2 3
| |
4 5
/ \ |
*6* 8 *7*
|
*9*get_leaf_paths(1) would return 1 row: {1, 3, 5, 7}
- get_leaf_paths(2) would return 2 rows: {2, 4, 6} and {2, 4, 8, 9}
Sample table:
CREATE TABLE graph (
id bigint PRIMARY KEY,
parent_id bigint,
FOREIGN KEY (parent_id) REFERENCES graph(id)
);
INSERT INTO graph (id, parent_id)
VALUES (0, NULL),
(1, NULL),
(2, 0),
(3, 1),
(4, 2),
(5, 3),
(6, 4),
(7, 5),
(8, 4),
(9, 8);SELECT get_leaf_paths.* FROM get_leaf_paths(0);
path
-----
{0, 2, 4, 6}
{0, 2, 4, 8, 9}
(2 rows)6 and 9 above are at different depths). The paths can be very deep (thousands or millions of elements), so I would also like to avoid the excessive memory usage of generating paths for every intermediate node.
Any ideas would be greatly appreciated. Thanks!
Jason Dreyzehner
(155 rep)
Apr 9, 2021, 05:10 AM
• Last activity: Apr 9, 2021, 05:58 AM
2
votes
0
answers
500
views
Drop intermediate results of recursive query in Postgres
I'm trying to aggregate the contents of a column from a [directed acyclic graph][1] (DAG) stored in a Postgres table. Each `dag` row has an `id`, `bytes`, and may also have a `parent` referencing another row. I'm trying to write a function which identifies every "tip" in the graph starting from a pa...
I'm trying to aggregate the contents of a column from a directed acyclic graph (DAG) stored in a Postgres table.
Each
dag row has an id, bytes, and may also have a parent referencing another row. I'm trying to write a function which identifies every "tip" in the graph starting from a particular parent id. The result needs to include each graph tip and its aggregated collected_bytes from the parent id to that tip. (The DAG can be very deep, so some collected_bytes arrays can have millions of elements.)
The function below works, but **memory usage grows quadratically as the collected_bytes get longer**. The results CTE keeps a copy of every iteration of collected_bytes until the end of the query, then the ranked CTE is used to select only the deepest node for each tip.
I think I'm approaching this incorrectly: **how can I do this more efficiently**?
Is it possible to instruct Postgres to drop the intermediate results as the recursive query is running? (So we can also skip the ranked CTE?) Is there a more natural way to achieve the result below?
DROP TABLE IF EXISTS dag;
CREATE TABLE dag (
id bigint PRIMARY KEY,
parent bigint,
bytes bytea NOT NULL,
FOREIGN KEY (parent) REFERENCES dag(id)
);
INSERT INTO dag (id, parent, bytes) VALUES (0, NULL, '\x0000'),
(1, NULL, '\x0100'),
(2, 0, '\x0200'),
(3, 1, '\x0300'),
(4, 2, '\x0400'),
(5, 3, '\x0500'),
(6, 4, '\x0600'),
(7, 5, '\x0700'),
(8, 4, '\x0800');
DROP FUNCTION IF EXISTS get_descendant;
CREATE FUNCTION get_descendant (input_id bigint)
RETURNS TABLE(start_id bigint, end_id bigint, collected_bytes bytea[], depth bigint)
LANGUAGE sql STABLE
AS $$
WITH RECURSIVE results AS (
SELECT id AS start_id, id AS end_id, ARRAY[bytes] AS collected_bytes, 0 AS depth
FROM dag WHERE id = input_id
UNION ALL
SELECT start_id,
dag.id AS end_id,
collected_bytes || dag.bytes AS collected_bytes,
depth + 1 AS depth
FROM results INNER JOIN dag
ON results.end_id = dag.parent
WHERE depth < 100000
),
ranked AS (
SELECT *, rank() over (PARTITION BY start_id ORDER BY start_id, depth DESC) FROM results
)
SELECT start_id, end_id, collected_bytes, depth FROM ranked WHERE rank = 1;
$$;0, which has two valid tips, an id of 6 and 8. The collected_bytes field is the aggregation of bytes along each path:
postgres=# SELECT get_descendant.* FROM get_descendant(0::bigint);
start_id | end_id | collected_bytes | depth
----------+--------+-------------------------------------------+-------
0 | 6 | {"\\x0000","\\x0200","\\x0400","\\x0600"} | 3
0 | 8 | {"\\x0000","\\x0200","\\x0400","\\x0800"} | 3
(2 rows)results before being ranked (and only the maximum depths selected):
postgres=# SELECT get_descendant.* FROM get_descendant(0);
start_id | end_id | collected_bytes | depth
----------+--------+-------------------------------------------+-------
0 | 0 | {"\\x0000"} | 0
0 | 2 | {"\\x0000","\\x0200"} | 1
0 | 4 | {"\\x0000","\\x0200","\\x0400"} | 2
0 | 6 | {"\\x0000","\\x0200","\\x0400","\\x0600"} | 3
0 | 8 | {"\\x0000","\\x0200","\\x0400","\\x0800"} | 3
(5 rows)
Jason Dreyzehner
(155 rep)
Apr 8, 2021, 10:57 PM
• Last activity: Apr 9, 2021, 05:16 AM
4
votes
1
answers
2172
views
How Graph Databases Store Data on Disk
I have seen these papers: - [TurboGraph](http://www.eiti.uottawa.ca/~nat/Courses/csi5387_Winter2014/paper1.pdf) - [GraphChi](https://www.usenix.org/system/files/conference/osdi12/osdi12-final-126.pdf) - [BiShard Parallel Processor](https://arxiv.org/pdf/1401.2327.pdf) - [G-Store](http://www.cs.ox.ac...
I have seen these papers:
- [TurboGraph](http://www.eiti.uottawa.ca/~nat/Courses/csi5387_Winter2014/paper1.pdf)
- [GraphChi](https://www.usenix.org/system/files/conference/osdi12/osdi12-final-126.pdf)
- [BiShard Parallel Processor](https://arxiv.org/pdf/1401.2327.pdf)
- [G-Store](http://www.cs.ox.ac.uk/dan.olteanu/papers/g-store.pdf)
- [NXgraph](https://arxiv.org/pdf/1510.06916.pdf)
- [GridGraph](https://www.usenix.org/system/files/conference/atc15/atc15-paper-zhu.pdf)
...and a few others. I am new to databases (other than having used them for web apps without understanding their internals), so I don't have much of a foundation on how to use the disk for storage.
I would like to know in general what these papers are doing for storing the graph on the file system. In taking a brief glance at them, they mention loading relevant subgraphs into memory from disk for efficient updates/querying. Some of them store the edges in one set of files (calling them "shards") and the vertices in another set of files (calling them "intervals"). Some have multiple different IDs, such as the "record ID (RID)" and "vertex ID" in [TurboGraph](http://www.eiti.uottawa.ca/~nat/Courses/csi5387_Winter2014/paper1.pdf) (Figure 1 below).
However, I haven't yet seen a full overview of how all the pieces fit together. Wondering if one could explain that.
Specifically:
1. How the data might be structured into files for a graph database (at a high level).
2. What must happen when querying/updating in terms of loading stuff into memory at a high level.
It is unclear to me so far what needs to be loaded into memory, and what specifically the IDs are for. I'm not sure if each page (>= 1MB typically) is loaded into memory and parsed somehow, or scanned by line-by-line, or something similar (basically not sure how the file is parsed/scanned, and if it is parsed into some sort of in-memory data structure or if you can do the graph traversal stuff directly on the file bytes). And I'm not sure what the IDs are for. In RDBMSs the ID is sometimes an incremented integer per table without other meaning. In these papers it seems the ID has more to do with the position of a vertex in a page plus some sort of offsets and such. Also, some papers store a large single line (it seems) for a vertex with all its edges (an adjacency list), but I wonder about if you have thousands or millions of edges per vertex what to do. If one could point out the relevant features to look for then doing further research would help bring this into more clarity.
Thank you so much for your time, I hope that makes sense.
---
Figure 1.
[ ](http://www.eiti.uottawa.ca/~nat/Courses/csi5387_Winter2014/paper1.pdf)
](http://www.eiti.uottawa.ca/~nat/Courses/csi5387_Winter2014/paper1.pdf)
](http://www.eiti.uottawa.ca/~nat/Courses/csi5387_Winter2014/paper1.pdf)
Lance Pollard
(221 rep)
Jun 29, 2018, 10:48 PM
• Last activity: Dec 10, 2020, 12:00 PM
-1
votes
2
answers
503
views
Graph Database - data modelling - linking multiple pairs of nodes using the same edge?
I am trying understand the concepts, which apply to data modeling using Graphs - specifically on SQL Server 2019. One thing I am unsure of is can the same edge be used to connect different pairs of nodes: - If I have three nodes PowerBI, SSAS, SQL Server - The in the pipeline i am trying to model th...
I am trying understand the concepts, which apply to data modeling using Graphs - specifically on SQL Server 2019.
One thing I am unsure of is can the same edge be used to connect different pairs of nodes:
- If I have three nodes PowerBI, SSAS, SQL Server
- The in the pipeline i am trying to model there are two 'Connects To' relationships:
Power BI -> SSAS -> SQL Server
- Can I use a single edge 'Connects To' to store the relationship between Power BI -> SSAS and also the relationship between SSAS -> SQL Server or should these be two separate edges?
Previously, have worked on both OLTP and OLAP databases. However, there seems to be a much smaller body of knowledge on best practices for developing data models using graphs.
Soap
(11 rep)
Dec 6, 2019, 05:51 AM
• Last activity: Nov 6, 2020, 07:23 AM
2
votes
1
answers
450
views
How to maintain order when modeling outline in graph database?
([TaskPaper](https://www.taskpaper.com/)) outlines have a natural hierarchy relationship, so a graph database seems like a great fit. Each item in the outline is a node of the graph that points to its parent and children. I also really like the idea of modeling TaskPaper tags as nodes that any tagge...
([TaskPaper](https://www.taskpaper.com/)) outlines have a natural hierarchy relationship, so a graph database seems like a great fit. Each item in the outline is a node of the graph that points to its parent and children. I also really like the idea of modeling TaskPaper tags as nodes that any tagged items point to.
However, there is one problem: the order of items is important in an outline, but a simple graph doesn't keep that information. What is the best way to maintain the order of items when an outline is stored as a graph?
The method should be efficient when items are added/removed. New items may be inserted before existing items, so a simple increasing counter/timestamp won't work.
The goal is to store and query a giant outline that can't fit in memory (just the necessary items are streamed to/from the user). Two common ways of querying this outline would be:
- Linear: get the first n=100 items when everything is "expanded."
- Breadth first, with depth first traversal of certain items: only get the top level items, fulling expanding a few selected items. (If fully expanding an item would exceed n=100 items, stop expanding.)
Common updates would be:
- Add/delete a new item somewhere in the hierarchy. Most inserts will probably be appending after the last child of an item. (Basic editing.)
- Add/delete a new sub-tree (Copy-paste a section of an outline.)
I don't think other database types would be better than a graph database, but I'm open to using other databases (relational, NoSQL, etc).
Leftium
(769 rep)
Mar 2, 2020, 07:12 PM
• Last activity: Nov 6, 2020, 04:11 AM
1
votes
0
answers
101
views
SQL Graph DB Tables not supporting OLE DB Fast Load?
I try to use SSIS to load in SQL Server Graph DB an edge table, based on the documentation from MSFT it should behave like any normal table, if I use the OLE DB Destination with regular table load it works (but is super slow), so i wanted to use “table or view - fast load” configuration looks as exp...
I try to use SSIS to load in SQL Server Graph DB an edge table, based on the documentation from MSFT it should behave like any normal table, if I use the OLE DB Destination with regular table load it works (but is super slow), so i wanted to use “table or view - fast load” configuration looks as expected but upon execution i get this error.
***An OLE DB record is available. Source: "Microsoft SQL Server Native Client 11.0" Hresult: 0x80004005 Description: "JSON data for INSERT/UPDATE of graph pseudocolumn '$edge_id' is malformed.”.***
based on my understanding the edge_id should be auto created, therefore I’m a bit surprised, is fast load not supported on graph tables, hence the documentation is incorrect or what did I miss here ?
nojetlag
(2927 rep)
Nov 1, 2020, 09:13 PM
Showing page 1 of 20 total questions