Database Administrators
Q&A for database professionals who wish to improve their database skills
Latest Questions
0
votes
1
answers
143
views
Make all users within group role inherit permissions
I have a group role that consists of around 1,000 users. Those users do not inherit group role permissions, and I would like to make them all inherit them instead. What would be the way to do it without writing 1,000 lines of PostgreSQL code?
I have a group role that consists of around 1,000 users. Those users do not inherit group role permissions, and I would like to make them all inherit them instead.
What would be the way to do it without writing 1,000 lines of PostgreSQL code?
TimesAndPlaces
(101 rep)
Oct 25, 2022, 10:24 AM
• Last activity: Jul 20, 2025, 01:06 AM
0
votes
1
answers
166
views
Pass information to another table with the same inherit
Suppose the following scenario ... I have two tables (A, B) that inherit from a Z table, the SGBD is postgresql, these tables do not have an additional column, my question is how to pass a row from table A to table B that have the same inheritance. The Table Z has a state column, with that column i...
Suppose the following scenario ... I have two tables (A, B) that inherit from a Z table, the SGBD is postgresql, these tables do not have an additional column, my question is how to pass a row from table A to table B that have the same inheritance.
The Table Z has a state column, with that column i decide which is the destiny of the data that has been inserted, this with a trigge, when execute a insert query the triger is activate and with condition is redirecte to child tables.
Now, if the state change, how can i pass to table A to table B.??
supose state is a varchar data type and the value is 'A' go to table A and if the value is 'B' go to table B, the constranint in the tables is something like that...
table A constraint.. CONSTRAINT only_A CHECK (state = 'A')
table B constraint.. CONSTRAINT only_A CHECK (state = 'B')
____________
|___Z_TABLE_|
| pk |
| col1 |
| col2 |
| col3 |
| state |
|___________|
_______________ ________________
|___A_TABLE____| |____B_TABLE____|
| INHERITS (Z) | | INHERITS (Z) |
|______________| |_______________|
i need to delete and reinsert in the other table or only with chage the value of state column ???
something more hard is... the table Z has a many relation with another tables...
Roberto Dominguez Cazarin
(1 rep)
Nov 18, 2019, 07:33 PM
• Last activity: Jul 10, 2025, 10:04 AM
0
votes
1
answers
720
views
Django Multi Table Inheritance and Preserving Child and Child History
Place can have many different one to one fields, that’s why it can have bookstore, restaurant, and hardware store. But can the same place be both a bookstore and a restaurant at the same time? Now if the bank and restaurant tables don't have the same pk as place, I would think the answer is yes. But...
Place can have many different one to one fields, that’s why it can have bookstore, restaurant, and hardware store. But can the same place be both a bookstore and a restaurant at the same time? Now if the bank and restaurant tables don't have the same pk as place, I would think the answer is yes. But I also know that unless you put parent_link=True on it, erasing the child row automatically deletes the parent row.
My use case is to preserve the history of Restaurant despite it’s having now become a Bookstore, and if a Restaurant is simultaneously a Bookstore, to be able to keep both places in my db. Is the best way to do this with a fk to each of the bookstores, restaurants and hardware stores instead of either a OneToOne or multi table inheritance? Or is there some other way I’m not aware of? This has to be a solved problem, but so far I haven't found it. I'm currently looking at NFL databases because players can be on more than one team, (albeit not at the same time), and they have a recorded history of their team and individual stats - to see if I can hack those into what I want.
I'm even willing to consider an ArrayField or Hstore. I'm on Postgres 9.4 and trying to maintain 3NF. All wisdom accepted. Thanks.
Malik A. Rumi
(377 rep)
Aug 24, 2016, 01:54 AM
• Last activity: May 27, 2025, 02:09 PM
1
votes
2
answers
488
views
Oracle MV requires object type to be defined as FINAL?
I want to create an Oracle 18c **materialized view (MV)** on a table that has a user-defined datatype called [ST_GEOMETRY][1]: - The MV would do a COMPLETE refresh on a schedule — on a local table. ------------ **Some info about ST_GEOMETRY:** [![enter image description here][2]][2] > The [ST_Geomet...
I want to create an Oracle 18c **materialized view (MV)** on a table that has a user-defined datatype called ST_GEOMETRY :
- The MV would do a COMPLETE refresh on a schedule — on a local table.
------------
**Some info about ST_GEOMETRY:**
 > The ST_Geometry data type implements the SQL 3 specification of
> user-defined data types (UDTs), allowing you to create columns capable
> of storing spatial data such as the location of a landmark, a street,
> or a parcel of land. It provides International Organization for
> Standards (ISO) and Open Geospatial Consortium, Inc. (OGC) compliant
> structured query language (SQL) access to the geodatabase and
> database. This storage extends the capabilities of the database by
> providing storage for objects (points, lines, and polygons) that
> represent geographic features. It was designed to make efficient use
> of database resources; to be compatible with database features such as
> replication and partitioning; and to provide rapid access to spatial
> data.
>
> ST_Geometry itself is an abstract, noninstantiated superclass.
> However, its subclasses can be instantiated. An instantiated data type
> is one that can be defined as a table column and have values of its
> type inserted into it.
The SQL definition of the user-defined datatype can be found here: dbfiddle .
CREATE OR REPLACE TYPE SDE."ST_GEOMETRY" (
...
) NOT final
*(Although, I'm guessing most of the logic is stored in the EXTPROC.)*
-----------------
**MV object types must be FINAL:**
There is a known issue when trying to create an MV on the ST_GEOMETRY user-defined datatype (ORA-30373 ):
> Creating an Oracle materialized view for a table containing an
> ST_Geometry attribute returns the following error:
>
> "ORA-30373: object data types are not supported in this context".
>
> Code:
> SQL> CREATE MATERIALIZED VIEW parcel_view
> 2 AS SELECT * FROM parcel@remote_server;
>
> CREATE MATERIALIZED VIEW parcel_view
> *
> ERROR at line 1:
> ORA-30373: object data types are not supported in this context
>
> Cause:
>
> Oracle's Advanced Replication functionality requires that **all**
> **object types be defined as FINAL** to participate within a materialized
> view.
> The reason that the ST_Geometry cannot be defined as FINAL is because
> the type contains subtypes used for type inheritance. Oracle does not
> allow a type with subtypes to be defined as FINAL.
>
> Esri is currently working with Oracle to address this issue and
> limitation. The following Oracle TAR file is available for reference:
> "6482996.992 - ORA-30373 MATERIALIZE VIEW UNABLE TO REPLICATE A TYPE
> WHICH CONTAINS SUBTYPES. Enhancement Request (ER) 6370112".
*Note: I've contacted ESRI support and they say there hasn't been any progress with Oracle regarding the enhancement request.*
-------------
**Question:**
Is there a way to workaround this issue?
- I ask because ESRI has a reputation of not being great with Oracle. So there is a
chance that they have misunderstood the issue or haven't gotten creative enough.
------------
**For example, what about the ONLY keyword?**
9.9 Materialized View Support for Objects
> For both object-relational and object materialized views that are
> based on an object **table**, if the type of the master object table
> is not FINAL, the FROM clause in the materialized view definition
> query must include the ONLY keyword.
>
> For example:
>
> CREATE MATERIALIZED
> VIEW customer OF cust_objtyp AS
> SELECT CustNo FROM ONLY HR.Customer_objtab@dbs1;
>
> Otherwise, the FROM clause must omit the ONLY keyword.
Notes:
- Unfortunately, that blurb is about object **tables**, not about object **columns** (I believe the ST_GEOMETRY user-defined datatype would be considered
an "object column").
- But I wonder if the concept of the ONLY keyword could be used to help with
the FINAL problem with the ST_GEOMETRY object column. Any ideas?
> The ST_Geometry data type implements the SQL 3 specification of
> user-defined data types (UDTs), allowing you to create columns capable
> of storing spatial data such as the location of a landmark, a street,
> or a parcel of land. It provides International Organization for
> Standards (ISO) and Open Geospatial Consortium, Inc. (OGC) compliant
> structured query language (SQL) access to the geodatabase and
> database. This storage extends the capabilities of the database by
> providing storage for objects (points, lines, and polygons) that
> represent geographic features. It was designed to make efficient use
> of database resources; to be compatible with database features such as
> replication and partitioning; and to provide rapid access to spatial
> data.
>
> ST_Geometry itself is an abstract, noninstantiated superclass.
> However, its subclasses can be instantiated. An instantiated data type
> is one that can be defined as a table column and have values of its
> type inserted into it.
The SQL definition of the user-defined datatype can be found here: dbfiddle .
CREATE OR REPLACE TYPE SDE."ST_GEOMETRY" (
...
) NOT final
*(Although, I'm guessing most of the logic is stored in the EXTPROC.)*
-----------------
**MV object types must be FINAL:**
There is a known issue when trying to create an MV on the ST_GEOMETRY user-defined datatype (ORA-30373 ):
> Creating an Oracle materialized view for a table containing an
> ST_Geometry attribute returns the following error:
>
> "ORA-30373: object data types are not supported in this context".
>
> Code:
> SQL> CREATE MATERIALIZED VIEW parcel_view
> 2 AS SELECT * FROM parcel@remote_server;
>
> CREATE MATERIALIZED VIEW parcel_view
> *
> ERROR at line 1:
> ORA-30373: object data types are not supported in this context
>
> Cause:
>
> Oracle's Advanced Replication functionality requires that **all**
> **object types be defined as FINAL** to participate within a materialized
> view.
> The reason that the ST_Geometry cannot be defined as FINAL is because
> the type contains subtypes used for type inheritance. Oracle does not
> allow a type with subtypes to be defined as FINAL.
>
> Esri is currently working with Oracle to address this issue and
> limitation. The following Oracle TAR file is available for reference:
> "6482996.992 - ORA-30373 MATERIALIZE VIEW UNABLE TO REPLICATE A TYPE
> WHICH CONTAINS SUBTYPES. Enhancement Request (ER) 6370112".
*Note: I've contacted ESRI support and they say there hasn't been any progress with Oracle regarding the enhancement request.*
-------------
**Question:**
Is there a way to workaround this issue?
- I ask because ESRI has a reputation of not being great with Oracle. So there is a
chance that they have misunderstood the issue or haven't gotten creative enough.
------------
**For example, what about the ONLY keyword?**
9.9 Materialized View Support for Objects
> For both object-relational and object materialized views that are
> based on an object **table**, if the type of the master object table
> is not FINAL, the FROM clause in the materialized view definition
> query must include the ONLY keyword.
>
> For example:
>
> CREATE MATERIALIZED
> VIEW customer OF cust_objtyp AS
> SELECT CustNo FROM ONLY HR.Customer_objtab@dbs1;
>
> Otherwise, the FROM clause must omit the ONLY keyword.
Notes:
- Unfortunately, that blurb is about object **tables**, not about object **columns** (I believe the ST_GEOMETRY user-defined datatype would be considered
an "object column").
- But I wonder if the concept of the ONLY keyword could be used to help with
the FINAL problem with the ST_GEOMETRY object column. Any ideas?
> The ST_Geometry data type implements the SQL 3 specification of
> user-defined data types (UDTs), allowing you to create columns capable
> of storing spatial data such as the location of a landmark, a street,
> or a parcel of land. It provides International Organization for
> Standards (ISO) and Open Geospatial Consortium, Inc. (OGC) compliant
> structured query language (SQL) access to the geodatabase and
> database. This storage extends the capabilities of the database by
> providing storage for objects (points, lines, and polygons) that
> represent geographic features. It was designed to make efficient use
> of database resources; to be compatible with database features such as
> replication and partitioning; and to provide rapid access to spatial
> data.
>
> ST_Geometry itself is an abstract, noninstantiated superclass.
> However, its subclasses can be instantiated. An instantiated data type
> is one that can be defined as a table column and have values of its
> type inserted into it.
The SQL definition of the user-defined datatype can be found here: dbfiddle .
CREATE OR REPLACE TYPE SDE."ST_GEOMETRY" (
...
) NOT final
*(Although, I'm guessing most of the logic is stored in the EXTPROC.)*
-----------------
**MV object types must be FINAL:**
There is a known issue when trying to create an MV on the ST_GEOMETRY user-defined datatype (ORA-30373 ):
> Creating an Oracle materialized view for a table containing an
> ST_Geometry attribute returns the following error:
>
> "ORA-30373: object data types are not supported in this context".
>
> Code:
> SQL> CREATE MATERIALIZED VIEW parcel_view
> 2 AS SELECT * FROM parcel@remote_server;
>
> CREATE MATERIALIZED VIEW parcel_view
> *
> ERROR at line 1:
> ORA-30373: object data types are not supported in this context
>
> Cause:
>
> Oracle's Advanced Replication functionality requires that **all**
> **object types be defined as FINAL** to participate within a materialized
> view.
> The reason that the ST_Geometry cannot be defined as FINAL is because
> the type contains subtypes used for type inheritance. Oracle does not
> allow a type with subtypes to be defined as FINAL.
>
> Esri is currently working with Oracle to address this issue and
> limitation. The following Oracle TAR file is available for reference:
> "6482996.992 - ORA-30373 MATERIALIZE VIEW UNABLE TO REPLICATE A TYPE
> WHICH CONTAINS SUBTYPES. Enhancement Request (ER) 6370112".
*Note: I've contacted ESRI support and they say there hasn't been any progress with Oracle regarding the enhancement request.*
-------------
**Question:**
Is there a way to workaround this issue?
- I ask because ESRI has a reputation of not being great with Oracle. So there is a
chance that they have misunderstood the issue or haven't gotten creative enough.
------------
**For example, what about the ONLY keyword?**
9.9 Materialized View Support for Objects
> For both object-relational and object materialized views that are
> based on an object **table**, if the type of the master object table
> is not FINAL, the FROM clause in the materialized view definition
> query must include the ONLY keyword.
>
> For example:
>
> CREATE MATERIALIZED
> VIEW customer OF cust_objtyp AS
> SELECT CustNo FROM ONLY HR.Customer_objtab@dbs1;
>
> Otherwise, the FROM clause must omit the ONLY keyword.
Notes:
- Unfortunately, that blurb is about object **tables**, not about object **columns** (I believe the ST_GEOMETRY user-defined datatype would be considered
an "object column").
- But I wonder if the concept of the ONLY keyword could be used to help with
the FINAL problem with the ST_GEOMETRY object column. Any ideas?
User1974
(1527 rep)
Jan 25, 2021, 03:23 AM
• Last activity: Apr 19, 2025, 04:04 AM
1
votes
1
answers
41
views
Database Design for Managing Main and Custom Scope Entities
I have a database consisting of a main scopes table (containing standard scopes), a projects table, and a configuration table linking scopes to projects. I now need to allow for custom scopes that are unique to each project. These custom scopes shouldn't be stored in the main scopes table so that us...
I have a database consisting of a main scopes table (containing standard scopes), a projects table, and a configuration table linking scopes to projects. I now need to allow for custom scopes that are unique to each project. These custom scopes shouldn't be stored in the main scopes table so that users don't see scopes from other projects when configuring their own. However, creating a separate table for custom scopes causes issues with referencing two different tables using foreign keys. What are some best practices or design patterns to handle this situation?
Nivethan
(11 rep)
Apr 11, 2025, 11:05 AM
• Last activity: Apr 12, 2025, 06:27 AM
0
votes
2
answers
364
views
Can Postgres inherited tables overlap
Is it possible to have single row in a parent table be visible in more than one inherited (child) table? Perhaps by inserting a row directly into the master table and then "making it visible" in one or more than one inherited table? To clarify: I want to insert into the parent table, then make that...
Is it possible to have single row in a parent table be visible in more than one inherited (child) table?
Perhaps by inserting a row directly into the master table and then "making it visible" in one or more than one inherited table?
To clarify:
I want to insert into the parent table, then make that row visible in one or more child tables. If the row is updated in one child table, the changes are immediately present in all tables where it is visible.
It does seem like this is not how Postgres inherited tables work, they appear to be more of a partitioning scheme.
I was thinking if I have a generic table with person information, then I could have a child table with that "person" and additional attributes, but if that person also belonged to a different class I could "make it visible" in another child table which would add different attributes. If however I changed the person's contact number, which is generic and comes from the parent table, then that would be reflected in all the child tables where this row is seen.
Johan
(623 rep)
Dec 29, 2016, 06:57 PM
• Last activity: Mar 16, 2025, 04:11 AM
0
votes
1
answers
367
views
When using class inheritance, can all PKs of the derived tables exist as PKs of the base table?
**Brief questions** 1. When class inheritance is used, the child table inherits the key from the parent, right? Thus, you `INSERT INTO` the parent and then the child? 1. [This][1] indicates that the PK of the child table (derived class) becomes FK in the parent table (base class). See "but now the p...
**Brief questions**
1. When class inheritance is used, the child table inherits the key from the parent, right? Thus, you
INSERT INTO the parent and then the child?
1. This indicates that the PK of the child table (derived class) becomes FK in the parent table (base class). See "but now the primary key of these tables also becomes a foreign key to the People table." That's not true is it? The examples indicate that the child tables reference the parent table. Did I misunderstand something?
2. Can the PK of both the child and parent tables be the same?
**Details**
I'm new to handling supertype-subtype instances in RDBs, but I've read a number of posts about three main options . The one I'm interested to implement is class inheritance where I have a base table with all common attributes and derived tables with attributes that are unique to each subtype.
I generically understand that class inheritance and table inheritance aren't the same. Based on the postgres documentation , table inheritance will allow for duplicate data in the child tables that I can't allow. Thus, I don't think table inheritance is a good way for me to go.
I'm interested in class inheritance because I need multiple different subtypes to be referenced as FK in a table. For example, I have a base class table vehicle and derived classes boat and car. I have another table for vehicle_maintenance. As a side note, I have many tables that are equivalent to vehicle_maintenance in that they can be applied to both boat and car. I also have many more subtypes than just boat and car with many attributes that are unique to each subtype.
Here's an example adapted from this post .
CREATE TABLE vehicle (
vehicle_id int PRIMARY KEY,
paint_type text,
-- // other common attributes
);
CREATE TABLE boat (
boat_id int PRIMARY KEY REFERENCES vehicle (vehicle_id),
propeller_type text,
water_exposure text,
-- // other attributes specific to boat ...
);
CREATE TABLE car (
car_id int PRIMARY KEY REFERENCES vehicle (vehicle_id),
steering_type text,
wheel_type text,
-- // other attributes specific to car ...
);
CREATE TABLE vehicle_maintenance_id (
vehicle_maintenance_id int,
date_complete datetime,
FOREIGN KEY (vehicle_id) REFERENCES vehicle (vehicle_id)
);paint_type would be repeated without any other attributes being UNIQUE, except the PK. This doesn't seem very normalized, but it's the only way I understand to get all of the PKs from the derived tables into one table without just doing an all-in-one table instead of class inheritance.
Am I just confusing myself, and the example I provided above is acceptable?
**Edit**
Perhaps I need to make this a separate question: I can't create composite keys based on attributes in the child tables and use them as PKs in the base table, right? This is because each child table will have unique attributes and the base table would require only one set of attributes to form the composite FK, correct?
Marion
(101 rep)
Aug 12, 2020, 12:46 AM
• Last activity: Jan 13, 2025, 05:05 AM
2
votes
2
answers
87
views
How to properly organize table schema for data with "inheritable" properties?
I came with some background in C++ so let me clarify the "inheritable" properties in context of my question. I have data which is used to setup and control some equipment (so-called "instrument methods", or "method properties" in my vendor's terminology). I have different equipment from different ve...
I came with some background in C++ so let me clarify the "inheritable" properties in context of my question.
I have data which is used to setup and control some equipment (so-called "instrument methods", or "method properties" in my vendor's terminology). I have different equipment from different vendors, however, most of the properties are just the same.
Because now I deal only with single instrument type I store all of the method properties directly in one table where each column represents some property while rows contain all necessary data for single "instrument method" record. For example, my columns may be the following: *temperature*, *flow*, *percent_b*, *gas_flow*, *gas_type*. But soon I will be dealing with several types of instruments so this question naturally arises.
Let's review the following example.
1. Method of equipment **B** contains (*b*) all of the properties of the method of equipment **A** (*a*) plus some extra own parameters (*b1*). So I can say that **A** is a direct ancestor of **B**: **A** -> **B**; *b* = *a* + *b1*.
2. Method of equipment **C** contains (*c*) only some of the properties of the method of equipment **A** (*a1*) plus some extra own parameters (*c1*). So I can say that **A** and **C** both have common ancestor **X** in the past: **X** -> ... -> ... -> **A** and **X** -> ... -> ... -> **C**; *c* = *a1* + *c1*
Case number 1 represents **B** being direct mod/upgrade of **A** (e. g. instruments from the same vendor, just consequent models) while case number 2 represents **C** being in the same class of instruments as **A** (even from different vendors but pretty much the same).
I know how to easily implement this with class hierarchy in C++ with just adding extra fields and other data structures where needed but I have no clue how to properly implement this in case of DB tables (if that's important I'm using MariaDB).
As for now I have an idea of possible solution. I've decided to store data for specific instrument models in separate specialized tables, e. g.:
1. Table **MODEL_A** contains the following columns: *id*, *temperature*, *flow*, *percent_b*
2. Table **MODEL_A1** contains the following columns: *id*, *temperature*, *flow*, *percent_b*, *percent_c*, *percent_d*
3. Table **MODEL_B** contains the following columns: *id*, *temperature*, *gas_flow*, *gas_type*
Also I need to store enumeration of supported equipment types (instrument models, in other words) in separate table. Finally, instead of storing all of possible data in one basic table (like with an example at the very beginning) I should store just the following rows of data in it: *id*, *instrument_type*, *method_id*. And here arises other complication. If I use only three columns - ID, reference to the instrument type (which is stored in separate table), reference to the actual data row in method table for specific equipment type - there should be some mechanism to ensure data consistency. I know how to apply foreign key constraints in simple cases (the whole column refers to another in second table) but I don't know how to tie these constraints with one extra constraint - selection of instrument type. Imagine that: end user of DB decides to change equipment type of the record in basic table. That action can invalidate foreign key reference because now we should refer to another table at all and it may (and, most likely, will) not contain proper data at old ID reference. I can prohibit changing instrument type at all, though, it isn't convenient and practical (much better solution would be to make necessary actions in GUI - I can highlight incompatible fields and hint next steps for end user). But in any case I can't leverage the benefit of using
ON DELETE and ON UPDATE clauses together with the whole foreign keys idiom because different rows in my basic methods table will refer to the different tables in DB which AFAIK is not supported in MariaDB (or any other RDBMS). It looks like I shall track the whole integrity by hand in my backend/frontend code.
So, I have the following questions:
1. Is such approach viable at all?
2. Is there a way to have references to different tables for a different rows of data?
2. Is there much better way to implement this in a RDBMS like MariaDB?
3. Are there RDBMSes much more suitable for such a task?
Drobot Viktor
(121 rep)
Dec 28, 2024, 07:41 AM
• Last activity: Jan 5, 2025, 12:33 AM
0
votes
1
answers
37
views
Postgres permissions on table create not propagated
we are working with a postgres database V13. We're facing a problem that previously permissions were just inherited/created when a new table was created. It is not working anymore, when I create a new table no permissions are set at all. In our database we have a user structure, where we have user g...
we are working with a postgres database V13. We're facing a problem that previously permissions were just inherited/created when a new table was created. It is not working anymore, when I create a new table no permissions are set at all.
In our database we have a user structure, where we have user groups, e.g. **group1**. Then we have a user belonging to that user group named **user1** and it inherits from **group1**. Next, there is a schema that grants specific default priveleges with **group1** being the grantor in that case. This schema is owned by user group **schema1**.
Now question Nr. 1: If I create a table as **user1**, shouldn't the default priveleges defined through the user group **group1** automatically be applied to that table? Because **user1** belongs to that group and inherits from it.
Question Nr. 2: the schema in which I create this table is owned by **schema1** user group. When I set the owner of the table to **schema1** does that have any implications for the table priveleges?
What I expected was a table that in the permissions has two entries:
1. **other_user_group1** read permissions granted by **user1** or **group1** through the default permissions
2. **schema1** all permissions granted by **schema1**
Maybe I have misunderstood how these permissions are inherited,so it would be great to further understand this. Also, if this is not how it works, how this has worked beforehand and what might have changed. Thanks so much for your help!
pau
(1 rep)
Nov 25, 2024, 01:46 PM
• Last activity: Nov 25, 2024, 01:49 PM
-1
votes
1
answers
64
views
How to INSERT a new record into 2 tables with FKEY inheritance?
Inheritance has been setup with FKEY instead of INHERITS due to FKEY limitation. My question: How to INSERT a new record into `bonds` table? ``` CREATE TABLE IF NOT EXISTS instruments ( id SERIAL, created_at timestamp with time zone DEFAULT CURRENT_TIMESTAMP NOT NULL, ticker varchar(255), type varch...
Inheritance has been setup with FKEY instead of INHERITS due to FKEY limitation.
My question: How to INSERT a new record into
bonds table?
CREATE TABLE IF NOT EXISTS instruments (
id SERIAL,
created_at timestamp with time zone DEFAULT CURRENT_TIMESTAMP NOT NULL,
ticker varchar(255),
type varchar(255),
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS bonds (
id int NOT NULL,
maturity date,
PRIMARY KEY (id),
CONSTRAINT fk_instruments FOREIGN KEY (id) REFERENCES instruments(id)
);
CREATE TABLE IF NOT EXISTS equities (
id int NOT NULL,
name varchar(255),
PRIMARY KEY (id),
CONSTRAINT fk_instruments FOREIGN KEY (id) REFERENCES instruments(id)
);
John Doe
(1 rep)
Sep 12, 2024, 08:21 AM
• Last activity: Sep 15, 2024, 12:39 AM
9
votes
2
answers
5115
views
Polymorphic Association - is it bad?
In the following schema: Collections Upvotes Reports Upvotes Reviews Upvotes I'm tempted to have a single `Upvotes` table with a single `"entityId"` column that stores either the `CollectionId`, `ReportId`, or `ReviewId`. There will also be an enum for `Type` - storing either `collection`, `report`,...
In the following schema:
Collections
Upvotes
Reports
Upvotes
Reviews
Upvotes
I'm tempted to have a single
Upvotes table with a single "entityId" column that stores either the CollectionId, ReportId, or ReviewId. There will also be an enum for Type - storing either collection, report, or review.
The entityId will always be required, and the logic will always make sure that inserts enforce uniqueness across each type.
The benefits of this is that adding another type is just a matter of expanding the enum. Everything will live on a single table with no redundancy.
The cost seems to be the added complexity on the logic side, which is contained to the one place in my application logic that inserts new entities into the table.
Practically speaking, is there anything wrong with this approach? What would be some other reasons to avoid this?
RobVious
(191 rep)
Dec 8, 2013, 05:01 PM
• Last activity: Jun 4, 2024, 12:44 PM
0
votes
1
answers
264
views
How to correctly deal with IDENTITY fields on parent/child tables when using inheritance in PostgreSQL
I have a rather simple question when playing with a PG 15.1 database. I've tried to set up a simple inheritance case: ```sql DROP TABLE IF EXISTS cities CASCADE; CREATE TABLE IF NOT EXISTS cities ( id INT UNIQUE PRIMARY KEY GENERATED ALWAYS AS IDENTITY, "name" TEXT, population REAL, elevation INT );...
I have a rather simple question when playing with a PG 15.1 database.
I've tried to set up a simple inheritance case:
DROP TABLE IF EXISTS cities CASCADE;
CREATE TABLE IF NOT EXISTS cities (
id INT UNIQUE PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
"name" TEXT,
population REAL,
elevation INT
);
CREATE TABLE IF NOT EXISTS capitals (
"state" CHAR(2) UNIQUE NOT NULL
) INHERITS (cities);
INSERT INTO cities (name, population, elevation)
VALUES ('City One', 25000, 430), ('Town Two', 18000, 380), ('Urban 3', 30000, 400), ('Metropolitan 4', 50000, 450);
INSERT INTO capitals (name, population, elevation, state)
VALUES ('Capital 1', 1200000, 550, 'AK'), ('Capital 2', 1030000, 540, 'ZA');NOTICE: drop cascades to table capitals
ERROR: Failing row contains (null, Capital 1, 1.2e+06, 550, AK).null value in column "id" of relation "capitals" violates not-null constraint
ERROR: null value in column "id" of relation "capitals" violates not-null constraint
SQL state: 23502
Detail: Failing row contains (null, Capital 1, 1.2e+06, 550, AK).SERIAL type instead. Which I don't really want to do.
So I also added the identity field on the child table:
DROP TABLE IF EXISTS cities CASCADE;
CREATE TABLE IF NOT EXISTS cities (
id INT UNIQUE PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
"name" TEXT,
population REAL,
elevation INT
);
CREATE TABLE IF NOT EXISTS capitals (
id INT PRIMARY KEY GENERATED ALWAYS AS IDENTITY, -- added
"state" CHAR(2) UNIQUE NOT NULL
) INHERITS (cities);
INSERT INTO cities (name, population, elevation)
VALUES ('City One', 25000, 430), ('Town Two', 18000, 380), ('Urban 3', 30000, 400), ('Metropolitan 4', 50000, 450);
INSERT INTO capitals (name, population, elevation, state)
VALUES ('Capital 1', 1200000, 550, 'AK'), ('Capital 2', 1030000, 540, 'ZA');SELECT statement seems to be OK:
SELECT * FROM capitals;
id | name | population | elevation | state
----+-----------+------------+-----------+-------
1 | Capital 1 | 1.2e+06 | 550 | AK
2 | Capital 2 | 1.03e+06 | 540 | ZA
(2 rows)SELECT * FROM cities;
id | name | population | elevation
----+----------------+------------+-----------
1 | City One | 25000 | 430
2 | Town Two | 18000 | 380
3 | Urban 3 | 30000 | 400
4 | Metropolitan 4 | 50000 | 450
1 | Capital 1 | 1.2e+06 | 550
2 | Capital 2 | 1.03e+06 | 540
(6 rows)twined_with to be able to link two cities as twin cities.
s.k
(424 rep)
Feb 9, 2024, 03:24 PM
• Last activity: Feb 9, 2024, 04:44 PM
0
votes
0
answers
27
views
Postgresql Inheritance : Parent can be in two Child and c
In postgres sql inheritance: Parent: Person Child : Professor Child : Student Student can be a Professor How to manage insert with solo parent ?
In postgres sql inheritance:
Parent: Person
Child : Professor
Child : Student
Student can be a Professor
How to manage insert with solo parent ?
KstorTroy
(1 rep)
Jan 26, 2024, 10:42 PM
0
votes
1
answers
91
views
Move row of a table to an inherited table in PostgreSQL
I have tables created as such: BEGIN; CREATE TABLE tag ( id SERIAL, name VARCHAR(255) UNIQUE NOT NULL, description VARCHAR(511) NOT NULL DEFAULT '', PRIMARY KEY(id) ); CREATE TABLE fandom ( id SERIAL, name VARCHAR(255) UNIQUE NOT NULL, link TEXT UNIQUE NOT NULL, PRIMARY KEY(id) ); CREATE TABLE chara...
I have tables created as such:
BEGIN;
CREATE TABLE tag (
id SERIAL,
name VARCHAR(255) UNIQUE NOT NULL,
description VARCHAR(511) NOT NULL DEFAULT '',
PRIMARY KEY(id)
);
CREATE TABLE fandom (
id SERIAL,
name VARCHAR(255) UNIQUE NOT NULL,
link TEXT UNIQUE NOT NULL,
PRIMARY KEY(id)
);
CREATE TABLE character (
fandom_id INT REFERENCES fandom(id), -- allowed to be null
link TEXT UNIQUE,
PRIMARY KEY(id)
) INHERITS (tag);
COMMIT;
Next I do something like
INSERT INTO tag (name) VALUES ('John Doe')
At insertion time I do not know if 'John Doe' is a character, but I can check afterwards. I would like to do something like
BEGIN;
DELETE FROM tag WHERE name='John Doe';
INSERT INTO character (name) VALUES ('John Doe');
COMMIT;
The problem, as I see it, is that the ID is incremented for the second 'John Doe' and now all foreign keys referencing the tag 'John Doe' by ID are off by one, if the deletion even works.
Is there a way to simply move the row of 'John Doe' from 'tag' to 'character'?
I'm a DB noob, so additional notes are welcome in the comments.
SK19
(101 rep)
Dec 23, 2023, 04:53 PM
• Last activity: Dec 23, 2023, 07:04 PM
0
votes
1
answers
28
views
Alerting system relationships and STI in PostgreSQL
I'm no expert in DBMS and trying to build up **an alerting system that can attach itself to many tables**, so I figured asking the question would help my architecture. [![many to many tables][2]][2] The thing that may confuse me a little is that you can have multiple alerts attached to **each model*...
I'm no expert in DBMS and trying to build up **an alerting system that can attach itself to many tables**, so I figured asking the question would help my architecture.
 The thing that may confuse me a little is that you can have multiple alerts attached to **each model** (sessions, events, organization) that are represented in tables in my database. One record of each model can have multiple different alerts ringing up.
The simplest way to solve this is to create a table such as
The thing that may confuse me a little is that you can have multiple alerts attached to **each model** (sessions, events, organization) that are represented in tables in my database. One record of each model can have multiple different alerts ringing up.
The simplest way to solve this is to create a table such as
The thing that may confuse me a little is that you can have multiple alerts attached to **each model** (sessions, events, organization) that are represented in tables in my database. One record of each model can have multiple different alerts ringing up.
The simplest way to solve this is to create a table such as
CREATE TABLE alerts (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
alert_type character varying(50) NOT NULL,
metadata jsonb,
session_id uuid REFERENCES sessions(id) ON DELETE DO NOTHING ON UPDATE CASCADE,
event_id uuid REFERENCES events(id) ON DELETE DO NOTHING ON UPDATE CASCADE,
organization_id uuid REFERENCES organizations(id) ON DELETE DO NOTHING ON UPDATE CASCADE,
created_at timestamp without time zone,
updated_at timestamp without time zone
);alerts and to represent the many-to-many a second table alerts_relations that has table_name and table_id to make sense of each other model/table it's attached to.
CREATE TABLE alerts (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
alert_type character varying(50) NOT NULL,
metadata jsonb,
created_at timestamp without time zone,
updated_at timestamp without time zone
);
CREATE TABLE alerts_relations (
id uuid DEFAULT uuid_generate_v4() PRIMARY KEY,
alert_id uuid REFERENCES alerts(id) ON DELETE CASCADE ON UPDATE CASCADE,
table_name character varying(50) NOT NULL,
table_id character varying(50) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone
);table_name and table_id and replace it with the following
CREATE TABLE session_alerts (
session_id uuid REFERENCES sessions(id) ON DELETE CASCADE ON UPDATE CASCADE
) INHERITS (alert_relations);
CREATE TABLE event_alerts (
event_id uuid REFERENCES events(id) ON DELETE CASCADE ON UPDATE CASCADE
) INHERITS (alert_relations);
CREATE TABLE organization_alerts (
organization_id uuid REFERENCES organizations(id) ON DELETE CASCADE ON UPDATE CASCADE
) INHERITS (alert_relations);
Laurent
(101 rep)
Dec 2, 2023, 08:23 PM
• Last activity: Dec 7, 2023, 02:45 AM
0
votes
1
answers
5274
views
Inheritance and foreign keys in Postgres
This is about using inheritance and foreign keys in Postgresql databases. Consider the following simplistic example whose structure is based on what I am building at the moment (but the specifics were contrived in realtime just for this question, so please excuse any shortcomings!): > Parent table1:...
This is about using inheritance and foreign keys in Postgresql databases.
Consider the following simplistic example whose structure is based on what I am building at the moment (but the specifics were contrived in realtime just for this question, so please excuse any shortcomings!):
> Parent table1: Person (columns: ID, Name). Child tables: Man, Woman.
>
> Parent table2: Relationship (columns: ID, Partner1 and Partner2). Child
> tables: Gay, Lesbian.
Each table has a primary key set on the column ID.
The table Relationship has two foreign keys set on columns Partner1 and Partner2 which reference the table Person (column ID).
The (inherited) tables Gay and Lesbian also need to have foreign keys set on their Partner1 and Partner2 columns. The question is whether these foreign keys should reference the parent table Person, or whether they should reference (as appropriate) the child tables Man and Woman.
The questions comes up because, as stated in the manual for v9.6, section 5.9.1 :
> **Caveats**
>
> ... A serious limitation of the inheritance feature is that indexes
> (including unique constraints) and foreign key constraints only apply
> to single tables, not to their inheritance children ...... These
> deficiencies will probably be fixed in some future release ...
To me, this (the fact that foreign keys do not apply across inherited tables and must be done separately) is a feature, and not a limitation. And a very useful feature too, as can be seen in the case of the aforementioned example:
When the child table Lesbian references the child table Woman (instead of the parent table Person), it is very easy to prevent errors of the sort where there's a lesbian relationship between two men!
 Of course, constraints can very well be imposed to achieve this, but it seems to me as though what I wrote above is a more elegant way of doing things. But I am also concerned about what the manual states towards the end - that the development team sees this as a problem, and might get rid of it. So I am also worried if my design would totally break after a future upgrade.
Any tips on the design above and suggestions for alternate ways would be most appreciated.
I would also be very grateful if there's someone from the Postgres dev team lurking around here, and is kind enough to comment.
Of course, constraints can very well be imposed to achieve this, but it seems to me as though what I wrote above is a more elegant way of doing things. But I am also concerned about what the manual states towards the end - that the development team sees this as a problem, and might get rid of it. So I am also worried if my design would totally break after a future upgrade.
Any tips on the design above and suggestions for alternate ways would be most appreciated.
I would also be very grateful if there's someone from the Postgres dev team lurking around here, and is kind enough to comment.
Of course, constraints can very well be imposed to achieve this, but it seems to me as though what I wrote above is a more elegant way of doing things. But I am also concerned about what the manual states towards the end - that the development team sees this as a problem, and might get rid of it. So I am also worried if my design would totally break after a future upgrade.
Any tips on the design above and suggestions for alternate ways would be most appreciated.
I would also be very grateful if there's someone from the Postgres dev team lurking around here, and is kind enough to comment.
ahron
(833 rep)
Aug 1, 2017, 07:53 AM
• Last activity: May 3, 2023, 11:03 PM
2
votes
1
answers
1484
views
Postgres natively partitioned tables - adding extra child columns
With Postgres native partitioning, can you add extra columns to a partition of the base table? Like: ```sql CREATE TABLE item ( tenant_id bigint NOT NULL, item_id bigint NOT NULL, kind text NOT NULL CHECK ( kind IN ('product', 'ingredient') ), PRIMARY KEY (tenant_id, item_id) ) PARTITION BY LIST (ki...
With Postgres native partitioning, can you add extra columns to a partition of the base table? Like:
CREATE TABLE item (
tenant_id bigint NOT NULL,
item_id bigint NOT NULL,
kind text NOT NULL CHECK ( kind IN ('product', 'ingredient') ),
PRIMARY KEY (tenant_id, item_id)
) PARTITION BY LIST (kind);
CREATE TABLE item_product PARTITION OF item (
extra_sku TEXT
) FOR VALUES IN ('product');
CREATE TABLE item_ingredient PARTITION OF item
FOR VALUES IN ('ingredient');CREATE TABLE] syntax doesn't seem to support adding columns on child tables, only adding constraints to existing columns, so I'm guessing it's not allowed.
Joe
(179 rep)
Jul 7, 2021, 01:59 AM
• Last activity: Apr 10, 2023, 01:01 PM
0
votes
1
answers
1010
views
Correct entity relationship diagram representation of a normalized table with a NOT NULL foreign key
## Intro Hi everyone, this is mainly a classification/theoretical question on the topic of **inheritance** and **normalization** techniques in database design and their appropriate representation in entity relational diagrams. In a practical implementation it doesn't present a challenge as you could...
## Intro
Hi everyone, this is mainly a classification/theoretical question on the topic of **inheritance** and **normalization** techniques in database design and their appropriate representation in entity relational diagrams. In a practical implementation it doesn't present a challenge as you could just set the attribute in question as **IS NOT NULL** and be done. However for a graphical representation I am a little confused on how to do it correctly.
Here is a github gist link with a interactive **mermaid** diagram representing a hypothetical scenario on a particular example: [gist](https://gist.github.com/papshmeare/dfe4b93e7c829b486f382e78e30c6318)
## Problem
The important part is in this section:
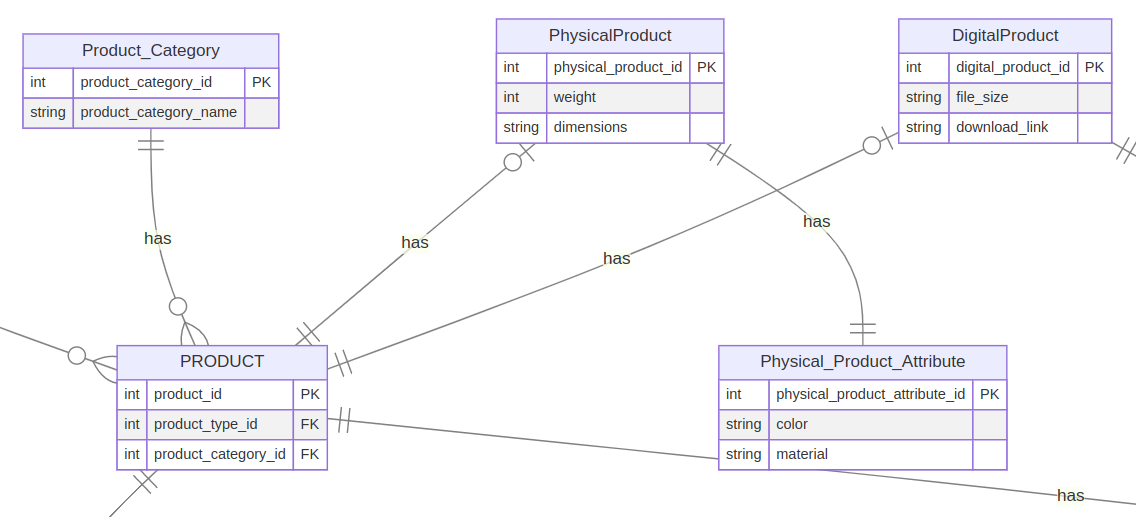
Assume we have an entity called PRODUCT which might have different types of attributes depending on the product in question(eg. Physical product/Digital product). For that reason we introduce two "subtables" whose PKs refer to a PRODUCTs FK attribute **product_type_id**. It is clear that a PRODUCT can only have a singular **product_type_id** but because it can be either **PhysicalProduct** or **DigitalProduct** what kind of relationship do these two "subtables" have with PRODUCT? So far I deduced that it must be **one to (zero or one)** as presented in the graph. That's where the problem(perhaps non-existent) lies.
If we have two **one to (zero or one)** relationships to a mandatory **IS NOT NULL** attribute doesn't it infer a possibility of two **one to zero** relationships visually or is it something not clicking in my head here and that is how it is supposed to be in this kind of scenario?
papshmeare
(3 rep)
Mar 27, 2023, 10:18 AM
• Last activity: Mar 27, 2023, 12:19 PM
0
votes
1
answers
135
views
table inheritance: TPH, TPT and single table vs taxonomies
according to [this post][1] and many others web resources, you can do table inheritance with `Table Per Hierarchy Inheritance`, `Table Per Type Inheritance` or `Single table` (single table for all sub classes). What about taxonomies? I do not know if "taxonomy" is the right word, I try to explain. I...
according to this post and many others web resources, you can do table inheritance with
Table Per Hierarchy Inheritance, Table Per Type Inheritance or Single table (single table for all sub classes).
What about taxonomies? I do not know if "taxonomy" is the right word, I try to explain.
I have 3 entities type:
- Organization (father)
- Restaurant (child)
- Hotel (child)
These are the tables I thought:
organization_type (id, name) // (ex. "restaurant", "hotel")
organization (id, name, organization_type_id)
organization_taxonomy (id, name) // (ex. "rooms_number", "tables_number")
organization_has_taxonomy (organization_id, organization_taxonomy_id, value)
If I need another organization type, I just need to:
1. add record to organization_type table
2. add records to organization_taxonomy table
Are there some drawbacks in this approach I am not thinking about?
Giacomo M
(163 rep)
Feb 19, 2023, 07:22 AM
• Last activity: Feb 19, 2023, 02:18 PM
2
votes
1
answers
102
views
Preserving foreign key properties when using Class Table Inheritance (or alternatives)
Imagine I have a table `events`, which `outdoor_events` and `indoor_events` inherit from. I have `activities` then `outdoor_activities` and `indoor_activities`. Assume it makes sense for outdoor and indoor to be wholly different structures, though I would be interested in alternative ways to model i...
Imagine I have a table
events, which outdoor_events and indoor_events inherit from. I have activities then outdoor_activities and indoor_activities. Assume it makes sense for outdoor and indoor to be wholly different structures, though I would be interested in alternative ways to model it than this inheritance.
If I want to preserve the property that all activities are linked to an event, the most straightforward method seems to be to use a foreign key in activities to events.
If I want to constrain outdoor activities to outdoor events, and same for indoor, it makes more sense to put a foreign key in each of the children. However, then the fact that every activity must be correlated with an event is left up to the table's children to implement it.
I could do both, but that in its simplest form is not an acceptable option to me because it is not normalized and which key to use is ambiguous – what if they differ?
To me the second option makes more sense, because it sounds stronger and will satisfy both conditions with a proper implementation.
What might I do to ensure that both of these properties are satisfied? Or is this structure flawed in principle?
Note: I don't believe that this is a duplicate of Using the same table for entities... because that question doesn't address pairing similar inherited tables.
thshea
(198 rep)
Jan 2, 2023, 05:44 AM
• Last activity: Jan 16, 2023, 11:06 AM
Showing page 1 of 20 total questions